Храним состояние веб-сокетов с помощью GenStage
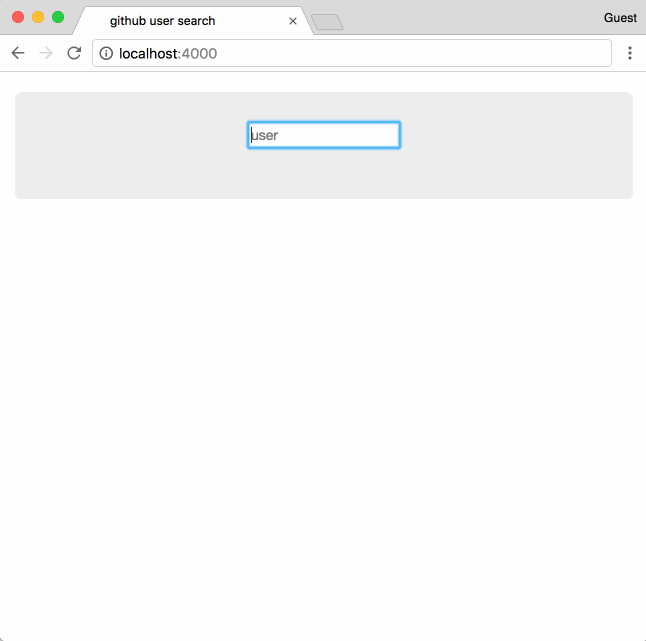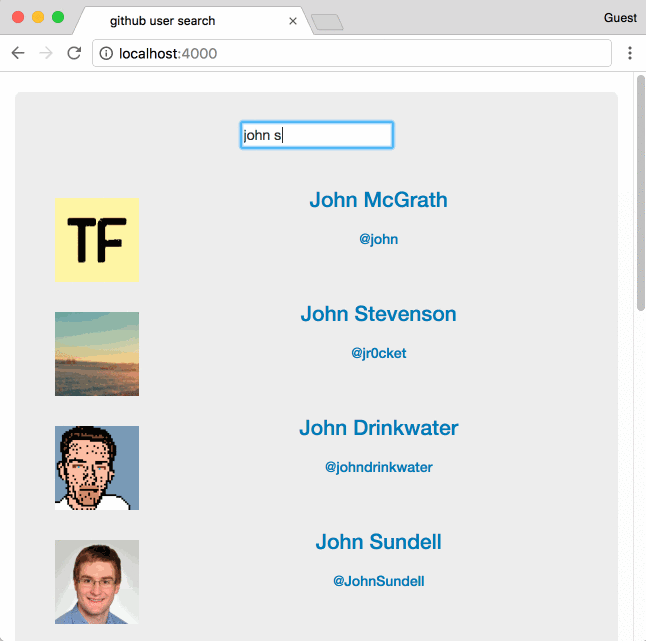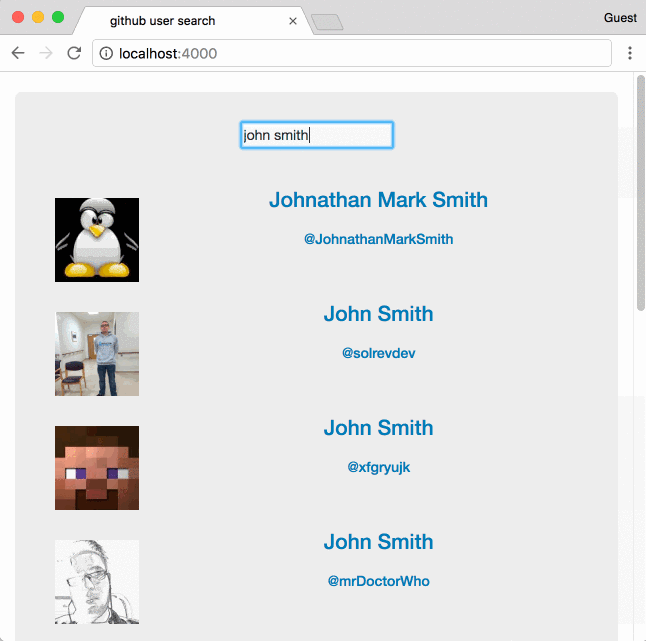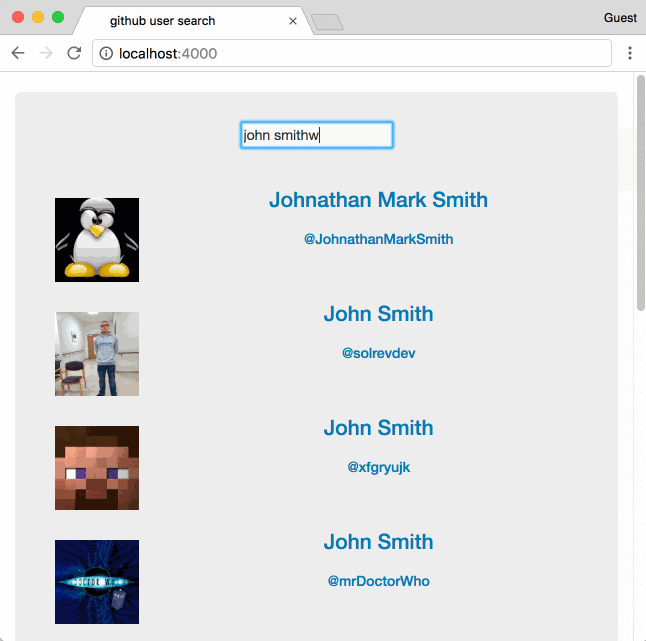
Недавно коллега поинтересовался, что я буду делать, если мне понадобится реализовать последовательный поиск через сторонний API. Задача многим хорошо знакома, уже давно придумано немало решений, но я решил внести свою лепту и попробовать кое-что другое.
Пробежимся по основным способам решения поставленной задачи, прежде чем я расскажу о том, почему для этого я выбрал GenStage и веб-сокеты.
Способы решения задачи
Первый способ – создавать отдельный запрос при появлении каждой новой буквы в поле поиска.
Пользователю это даст ощущение “умного” поиска с автодополнением , что, собственно, нам и нужно. Это как раз то, что из коробки делает механизм последовательного поиска платформы Algolia.
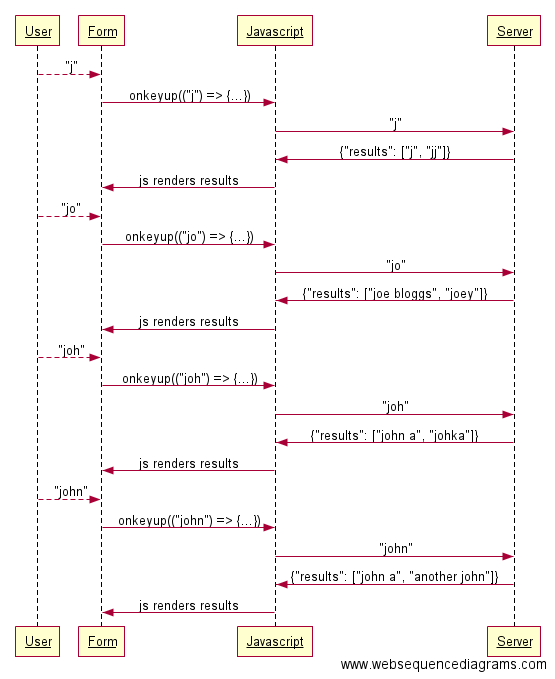
Я пытался найти информацию o концепции debounce в документации Algolia, Поиск – дело сложное.
Возможно, возникнет необходимость ограничить время и частоту отправки запросов к серверу. Быть может, нужно подключиться к API с ограничением на количество запросов, или вам просто не нравится затея посылать запрос после каждого нажатия клавиши. В конце концов, может, у вас собственный сервер, и вы не хотите посылать к нему столько запросов! Если это так, то, думаю, следующее решение покажется вам более целесообразным:
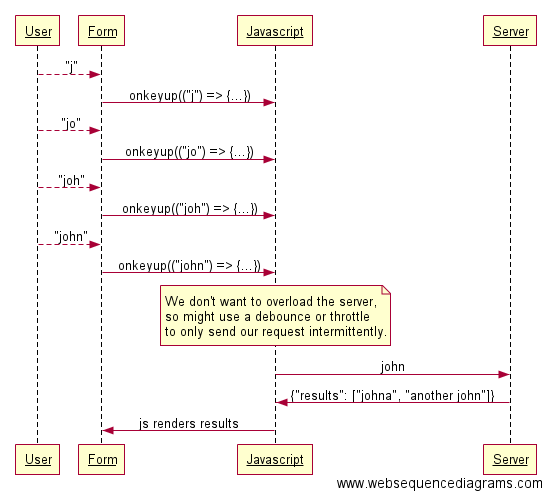
Согласно приведенной схеме, вместо того, чтобы беспокоить сервер после каждого изменения в поле поиска, используется debounce или throttle для сокращения числа таких запросов. Поставщику API это понравится.
Такие способы прекрасно подойдут для решения большинства практических задач, но каждый из них несовершенен:
-
Посылая запрос после каждого нажатия клавиши, мы не можем знать наверняка, дошел ли он до сервера, что становится проблемой, если на сервере установлено ограничение на количество запросов;
-
С помощью функции
debounce()запрос посылается только если пользователь ничего не печатал в течение заданного количества времени. Это мешает получить ощущение мгновенного поиска с автодополнением; -
С помощью функции
throttle()запрос посылается по прошествии определённого интервала времени. Всё бы ничего, но может случиться ситуация, при которой в некоторых отдельных задачах запросы будут посылаться чаще, чем при использовании других методов; -
Так или иначе, после отправки запроса необходимо ожидать ответ. В идеале, зачем вообще ждать? Почему бы не обработать результаты тогда, когда сервер сможет их предоставить?
Мысли о новом подходе
По правде говоря, каждое из вышеописанных решений хорошо для определенных целей. В моём случае нужно разработать механизм последовательного поиска через сторонний API, где есть ограничение на количество запросов в единицу времени, которого я хочу избежать.
В то же время мне бы хотелось, чтобы пользователь мог видеть промежуточные результаты поиска по мере ввода текста и не беспокоился о том, что лимит запросов будет превышен. Значит, вариант с функцией debounce выбывает из игры.
Внешний API, с которым я работаю (GraphQL API на GitHub’s), содержит ограничение 5000 запросов в час. Значит, можно не беспокоиться о его превышении, если посылать не более 1,38 шт. запросов в секунду.
Я мог бы использовать throttle, но недостаток этого метода в том, что он не учитывает предыдущие действия. Если за последние 5 секунд не было ни одного запроса, то, по идее, можно послать сразу пять прямо сейчас, не беспокоясь о превышении лимита.
Только представьте, если ваше приложение научится различать следующие два состояния и действовать по-разному в соответствии с каждым из них:
-
За последнюю секунду уже был отправлен один запрос, значит, чтобы не превысить ограничение в 1 запрос в секунду, нужно подождать;
-
За последние две секунды не было создано ни одного запроса, значит, можно послать два прямо сейчас.
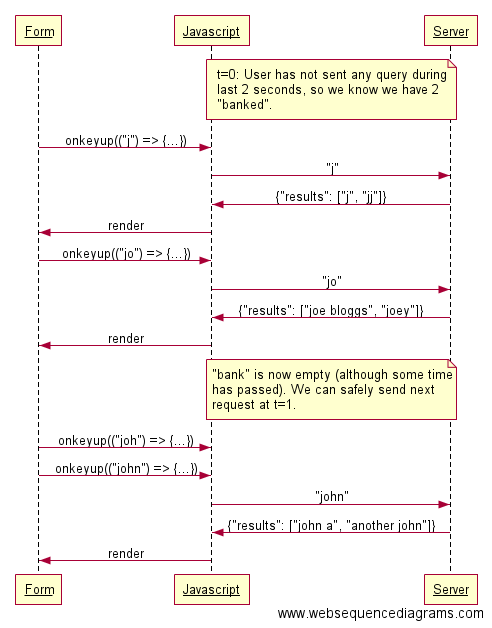
Данный подход в два раза эффективнее подхода с использованием функции throttle. Во-первых, неиспользованные запросы копятся в пределах лимита, и их можно использовать позже. Во-вторых, запросы, лежащие в “копилке”, можно использовать в большом количестве единовременно, как только это понадобится.
Думаю, это вполне реализуемо на javascript, но на деле такая модель – один из случаев, для которых предназначен GenStage, поэтому я и решил использовать его для своего сервера. Для меня это вполне оправданный ход, особенно потому, что мне хотелось бы добавить кое-что своё к уже существующим немногочисленным примерам использования GenStage на практике.
GenStage
Вряд ли у меня получится объяснить, что такое GenStage, лучше определения из официальной документации:
GenStage – новое поведение Elixir для обмена событиями между процессами с учётом “противодавления”. Разработчикам, использующим GenStage, стоит беспокоиться только о том, как создаются, обрабатываются и потребляются данные. Диспетчеризация данных и обеспечение противодавления происходят автоматически.
Используя GenStage, можно оперировать этапами, выступающими либо в качестве производителя, создающего события, либо в качестве потребителя, запрашивающего события у производителя, как только они появляются. Применительно к нашему случаю, можно превратить в этапы каждое из следующих действий:
-
Запоминание последнего запроса после ввода данных пользователем;
-
Обработка последнего запроса со скоростью, не превышающей заданную;
-
Отправка запроса на сервер.
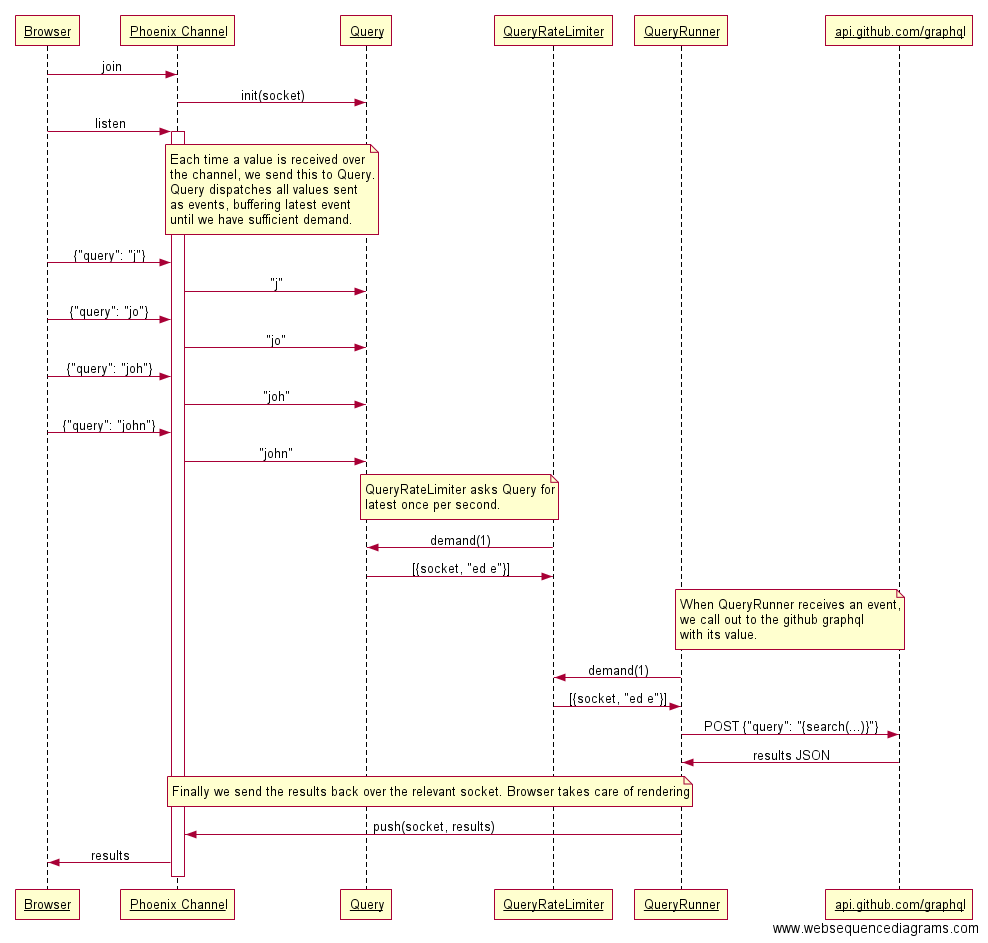
Приведенная ниже схема даст приблизительное представление об операциях с данными в системе, где Query, QueryRateLimiter, и QueryRunner – этапы модели GenStage:
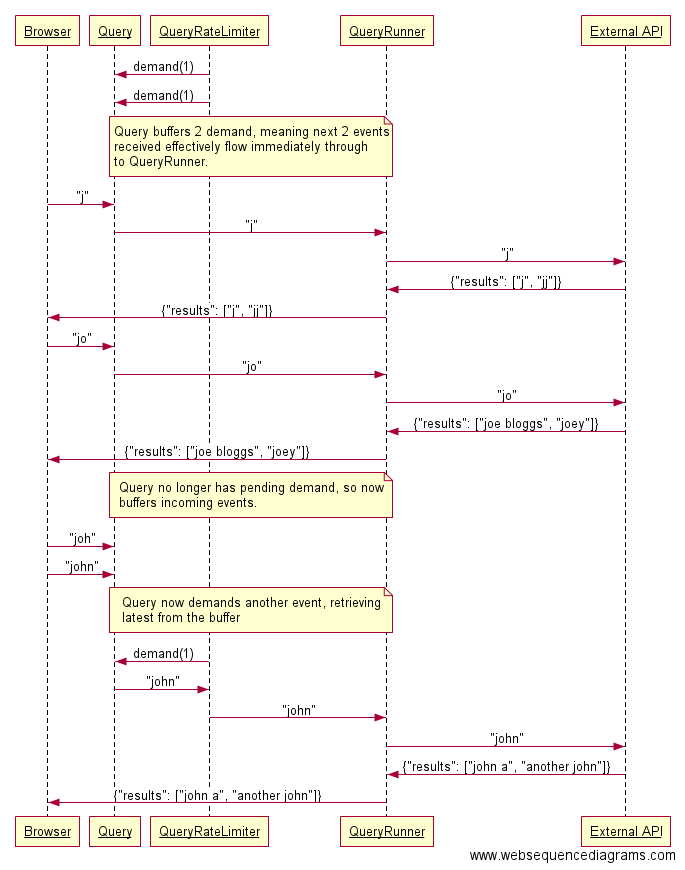
Согласно данной схеме, браузер посылает все события на Elixir-сервер. Получаем пайплайн GenStage, состоящий из трех этапов:
-
Queryили производитель. Этот модуль считывает введенные пользователем значения и превращает каждое из них в событие. -
QueryRateLimiterили производитель-потребитель. Один раз в секунду запрашивает события уQuery. Если уQueryесть готовое событие,QueryRateLimiterполучит его, в противном случае запрос помещается в буфер до тех пор, пока не появится новое событие. -
QueryRunnerили потребитель. Получив событие отQueryRateLimiter, запрашивает новое, прежде чем отправить его к внешнему API.
Такая схема позволяет более эффективно отслеживать количество запросов к API, чем другие рассмотренные ранее способы. Однако нельзя быть уверенным, что каждый запрос браузера дойдет до API.
Кроме того, чтобы запрос все-таки дошёл до конца, придётся пересылать его в два захода: от браузера к серверу Elixir, а затем уже к API. Честно говоря, хотелось бы избежать подобных действий с запросами. В любом случае нужно еще подумать о том, как предоставить пользователю ответ на его запросы.
Веб-сокеты
Использовать Elixir было удачным решением, ведь его фреймворк Phoenix до невозможности упрощает работу с веб-сокетами.
Создав пайплайн GenStage, и сделав так, чтобы клиент подключался через веб-сокет, можно обрабатывать события в свободное время, как это было описано выше, а затем через то же соединение посылать результаты обратно:
Реализация
Теперь, когда у нас есть представление о структуре системы, можно взяться за её реализацию. Ниже приведён код для каждого из трёх модулей и описание выполняемых ими действий.
Query
defmodule GithubProfiler.Query do
use GenStage
# Client
def start_link(socket), do: GenStage.start_link(__MODULE__, socket)
def update(pid, event), do: GenStage.cast(pid, {:notify, event})
# Server
def init(socket), do: {:producer, socket, buffer_size: 1}
def handle_cast({:notify, event}, socket) do
{:noreply, [{socket, event}], socket}
end
def handle_demand(_demand, state), do: {:noreply, [], state}
end
Модуль Query совсем небольшой. Основные действия:
-
Вызывается функция
start_link(socket), гдеsocket– это структура, представляющая собой соединение с веб-сокетом, к которому привязан запрос; -
Вызывается функция
init/1, определяющая, что данный этап является производителем и что единовременно в буфере будет храниться только одно событие (об этом чуть позже); -
Как только запрос переходит к
socket, вызывается функцияupdate/2с указанием PID прежде запущенного процесса и входящего запроса; -
Вызывается функция
handle_cast/2, которая сразу же пытается передать событие указанному потребителю; -
Поток входящих запросов будет обработан с помощью буфера, поэтому
handle_demand/2не возвращает никаких результатов.
Данная схема отлично подходит для решения поставленной задачи, так как:
-
Если количество исходящих запросов превышает допустимое значение (больше одного запроса в секунду), они будут храниться во внутреннем буфере GenStage. Для буфера задано ограничение равное единице, то есть запоминаться будет только последнее событие (незачем показывать пользователю устаревшие данные);
-
Если количество входящих событий меньше положенного (например, если за 5 секунд не было ни одного события, но на них было 4-5 запросов), это тоже помещается в буфер. Следовательно, в следующий раз можно будет послать 5 событий подряд, одно на каждое последующее нажатие клавиши.
В перспективе было бы неплохо подумать о ручном управлении буферами, чтобы держать запросы под контролем. В данной статье эта тема не рассматривается, так как в моём приложении всё и без того прекрасно работает, но насколько я понимаю, запросов событий может быть сколько угодно, и, на мой взгляд, этот параметр нужно ограничить.
QueryRateLimiter
defmodule GithubProfiler.QueryRateLimiter do
use GenStage
# Client
def start_link(:ok), do: GenStage.start_link(__MODULE__, :ok)
# Server
def init(:ok), do: {:producer_consumer, %{}}
def handle_subscribe(:producer, opts, from, producers) do
pending = opts[:max_demand] || 1
interval = opts[:interval] || 1000
producers =
producers
|> Map.put(from, {pending, interval})
|> ask_and_schedule(from)
{:manual, producers}
end
def handle_subscribe(:consumer, _opts, _from, consumers) do
{:automatic, consumers}
end
def handle_cancel(_, from, producers), do: Map.delete(producers, from)
def handle_events(events, _from, state), do: {:noreply, events, state}
def handle_info({:ask, from}, producers) do
{:noreply, [], ask_and_schedule(producers, from)}
end
defp ask_and_schedule(producers, from) do
case producers do
%{^from => {pending, interval}} ->
GenStage.ask(from, pending)
Process.send_after(self(), {:ask, from}, interval)
producers
%{} ->
producers
end
end
end
Этот модуль уже посложнее:
-
Как и в случае с производителем, этап начинается с вызова
start_link/1, которая в свою очередь обращается кinit/1. Этап инициализируется как производитель-потребитель, а его состояние представляет собой пустой map; -
Как только модуль будет привязан к производителю (
Query), вызываетсяhandle_subscribe/4. Она запрашивает PID производителя, ссылку вfromи помещает их в состояние производителя вместе со значениями дляpendingиinterval. Следом вызываем функциюask_and_schedule/2с обновлённым состоянием и новый производитель, прежде чем возвратить кортеж, обозначающий, что этот этап запросит события в ручном режиме; -
В функции
ask_and_schedule/2применяютсяpendingиinterval. Сначала обратимся к производителю с запросом ожидающих событий. Функцияhandle_events/3позаботится о каждом из них, оставив их без изменений; -
Затем воспользуемся
interval, чтобы послать сообщение кself()по прошествии обозначенного времени. Как толькоhandle_info/2получит это сообщение, вызываем ещё разask_and_schedule/2и цикл начинается сначала.
QueryRunner
defmodule GithubProfiler.QueryRunner do
use GenStage
import Phoenix.Channel, only: [push: 3]
# Client
def start_link(:ok), do: GenStage.start_link(__MODULE__, :ok)
# Server
def init(:ok), do: {:consumer, :ok}
def handle_events([{_socket, ""}], _from, state), do: {:noreply, [], state}
def handle_events([{socket, query}], _from, state) do
GithubProfiler.Search.run(query).body
|> push_results(socket)
{:noreply, [], state}
end
defp push_results(results, socket) do
push socket, "results", %{"results" => results}
end
end
И наконец, потребитель. Всё, что делает этот модуль, – это устанавливает соединение с QueryRateLimiter и обрабатывает события после их получения. Если входящее событие содержит запрос значения, оно отправляется к внешнему API (в коде этого нет, т. к. в рамках данной статьи это не имеет значения). Как только будут получены результаты, можно передать их через веб-сокет, на который ссылается событие.
Веб-сокет
Благодаря каналам Phoenix реализовать серверную часть веб-сокета несложно. Единственная сложность – это привязка GenStage к сокету.
defmodule GithubProfiler.Web.TypeaheadChannel do
use GithubProfiler.Web, :channel
def join("typeahead:public", _payload, socket) do
send(self(), :after_join)
{:ok, socket}
end
def handle_info(:after_join, socket) do
{:ok, producer_pid} = setup_genstage(socket)
{:noreply, assign(socket, :producer_pid, producer_pid)}
end
def handle_in("search", %{"query" => query}, socket) do
GithubProfiler.Query.update(socket.assigns.producer_pid, query)
{:noreply, socket}
end
defp setup_genstage(socket) do
{:ok, producer} = GithubProfiler.Query.start_link(socket)
{:ok, producer_consumer} = GithubProfiler.QueryRateLimiter.start_link(:ok)
{:ok, consumer} = GithubProfiler.QueryRunner.start_link(:ok)
GenStage.sync_subscribe(producer_consumer, to: producer)
GenStage.sync_subscribe(consumer, to: producer_consumer)
{:ok, producer}
end
end
Здесь выполняются следующие действия:
-
После подсоединения к каналу организовываем пайплайн GenStage, помещая сокет в состояние производителя, а PID производителя в значение
assignсокета; -
Как только в канал поступят события поиска, передадим их модулю
Queryвместе с PID сокета, что заставит производитель отправить событие.
Фронтенд
Фронтенд для всего этого я писал на Elm. Статья посвящена не этой теме, да и я только начал с ним разбираться, но код можно найти здесь, а дальше вкратце о том, что было сделано:
-
Elm-программа при загрузке инициализирует модель, в которой хранятся текущий запрос и результаты. Подключаемся к каналу
typeahead:publicи создаём подписку на события. -
Рендерим вывод
onInput. Посылаем функции обновления сообщениеSearch, выводя текущее значение через сокет. -
Когда результаты возвращаются через канал, создаётся сообщение обновления
Results. Ответ в формате JSON декодируется, и модель обновляется в соответствии с полученными результатами. После этого происходит обновление представления.
Заключение
Соединив все части воедино, получаем рабочее решение, которым я вполне доволен. Я провёл неплохой эксперимент, но если бы мне захотелось пойти дальше, например, сделать модель пригодной для развёртывания в продакшн, пришлось бы подробнее остановиться на некоторых моментах:
-
Учесть то, что ограничение по количеству запросов распространяется на несколько клиентов;
-
Использовать супервизоры для процессов GenStage;
-
Разобраться с тем, что Phoenix разрывает связь с веб-сокетом после 60 секунд простоя;
-
Подробнее изучить схему работы GenStage.
Это отличный шанс узнать больше о GenStage, и, устранив эти пробелы, можно получить отличное программное решение. Думаю, мной был реализован неплохой способ добавления состояния к соединению веб-сокета: мне удалось заставить его работать асинхронно и после этого посылать результаты через сокет.
Исходный код приведенной модели можно найти здесь. Буду рад любым комментариям.