Масштабируемое приложение на Эликсире: от зонтичного проекта к распределённой системе
Абстракции OTP Эликсира и Эрланга буквально вынуждают разработчиков разбивать программы на независимые части. Серверы GenServer инкапсулируют элементы бизнес-логики на микроуровне, в то время как приложения являются более общей (сервисной) составляющей системы. Сложные программы, написанные на Эликсире, всегда представляют собой набор взаимодействующих OTP-приложений.
Основной вопрос, возникающий в процессе создания таких программ, — это вопрос о разделении сложной системы на составные части. Но ещё более важной проблемой является организация связи между частями.
В данной статье приведены некоторые принципы проектирования при разработке более или менее сложных проектов на Эликсире. Мы поговорим о том, как разбивать проект на более мелкие поддерживаемые микросервисы (приложения) и как создавать внутри них модули, используя «контексты».
Но всё же основное внимание будет уделено проектированию гибких интерфейсов между приложениями на Эликсире. Вы увидите, как они будут меняться в процессе перехода от простого зонтичного проекта к распределённой системе. Будут рассмотрены такие подходы, как удалённый вызов процедуры Эрланга, распределённые задачи и HTTP-протокол. И в качестве бонуса вы узнаете, как ограничить конкурентный доступ к микросервисам.
Зонтичный проект
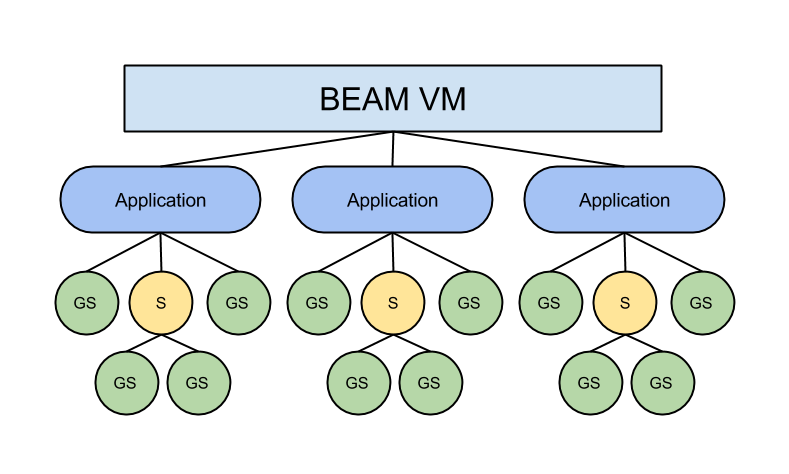
Структура зонтичного проекта на Эликсире позволяет разбить сложную логику на отдельные части в самом начале процесса разработки, и в то же время хранить всё в одном репозитории. Отсюда следует, что можно начать разработку будущих микросервисов без лишних усилий.
Вот этот демо-проект сегодня послужит нам в качестве примера. Проект называется ml_tools, а в полном варианте «Machine Learning Tools». Он позволяет пользователям применять к своим данным различные модели предсказания и выбирать из них наиболее подходящую. Им также предоставляется возможность выбора различных алгоритмов и визуализации результатов.
Принципы разделения проекта на несколько приложений достаточно очевидны и определяются из требований:
datasets— приложение, отвечающее за операции с данными: создание, чтение и обновление.utils— набор вспомогательных сервисов для предварительной обработки и визуализации данных.models— сервис, реализующий различные алгоритмы предиктивного моделирования: линейная модель, «случайный лес», метод опорных векторов.main— приложение верхнего уровня, задействующее остальные приложения и API верхнего уровня.
Каждое приложение запускается под контролем отдельного супервизора, а следовательно, является независимым сервисом.
apps/
datasets/
lib/
datasets/
fetchers/
fetchers.ex
aws.ex
kaggle.ex
collections/
...
interfaces/
fetchers.ex
collections.ex
models/
utils/
main/
...
Разбив логику верхнего уровня на несколько частей, рассмотрим каждую из них более подробно. Внутри каждого приложения код следует структурировать в виде модулей или наборов модулей. Можно определить модули верхнего уровня, основываясь на контекстах конкретного приложения.
К примеру, приложение datasets отвечает за хранение наборов данных в своей базе данных и выборку данных из других источников. Значит, приложение будет иметь две папки в директории lib/datasets: «collections» и «fetchers». В каждой из них будет присутствовать файл с расширением .ex, реализующий интерфейс контекста и другие вспомогательные модули.
Заглянем в папку lib/datasets/fetchers. В ней находится модуль Datasets.Fetchers, реализующий интерфейс для fetchers-контекста — функции, возвращающие данные с платформ AWS и Kaggle. Помимо этого, есть Datasets.Fetchers.Aws и Datasets.Fetchers.Kaggle, реализующие доступ к соответствующим источникам данных.
Такое же разделение по контекстному признаку можно осуществить и в остальных приложениях. Приложение models разбить по алгоритмам: Models.Lm (линейная модель), Models.Rf (случайный лес). Приложение utils отвечает за предварительную обработку данных (Utils.PreProcessing) и визуализацию (Utils.Visualization).
И осталось последнее приложение верхнего уровня (main), использующее все остальные микросервисы. Оно имеет несколько контекстов: Модуль Main.Zillow для конкурса от Zillow и Main.Screening для задачи по улучшению алгоритма досмотра пассажиров.
Все приложения подключены к приложению Main в списке зависимостей в Main.Mixfile:
defp deps do
[
{:datasets, in_umbrella: true},
{:models, in_umbrella: true},
{:utils, in_umbrella: true}
]
end
Таким образом, главному приложению доступны модули всех других.
Итак, в общем случае существуют три уровня организации кода в проектах, написанных на Эликсире:
-
Уровень сервиса — наиболее очевидный способ разбиения сложных систем на отдельные приложения (
datasets,models,utils). -
Уровень контекста — разделение ответственности внутри того или иного сервиса с помощью реализации модулей контекста (
Datasets.Fetchers, Datasets.Collections). -
Уровень реализации — создание нескольких модулей, определяющих функции и структуры данных (
Datasets.Fetchers.Aws,Datasets.Fetchers.Kaggle).
Плюсы и минусы зонтичного проекта
Как было отмечено выше, главное преимущество зонтичного проекта — хранение кода в одном месте и возможность использовать его целиком на стадиях разработки и тестирования. Можно экспериментировать с целой системой и, самое главное, тестировать все взаимодействующие компоненты в интеграционных тестах, что действительно важно на ранних стадиях разработки проекта.
В то же время проект разделён на несколько относительно независимых частей и готов к масштабированию.
Работая на других языках программирования, обычно создают один монолитный проект, а потом уже пытаются поместить некоторые части в отдельные приложения. Всё потому, что микросервисный подход невероятно усложняет процесс разработки.
Однако пора бы подумать и об инкапсуляции.
Наверняка вы заметили, что подключение всех приложений к главному в его зависимостях не есть хорошо.
Эликсиру не хватает конструкций для должной реализации инкапсуляции. Все, что у него есть, — это модули и функции (публичные и приватные). Если указать другой проект в зависимостях, то станут доступны все его модули, а значит, и все публичные функции. Реализация подбора данных для Zillow в главном приложении будет выглядеть так:
defmodule Main.Zillow do
def rf_fit do
Datasets.Fetchers.zillow_data
|> Utils.PreProcessing.normalize_data
|> Models.Rf.fit_model
end
end
Datasets.Fetchers, Utils.PreProcessing и Models.Rf — модули других приложений. Такое беспечное использование модулей из других приложений приведёт к объединению сервисов и превращению системы обратно в монолит.
С одной стороны, хотелось бы, чтобы все части проекта были доступны на стадиях разработки и тестирования, но при этом необходимо каким-то образом запретить связывание приложений.
Единственный способ это осуществить — создать соглашения о том, какие функции одного приложения могут быть использованы в другом. Лучше всего вытащить все публичные функции и поместить их в отдельные модули интерфейса.
Модули интерфейса
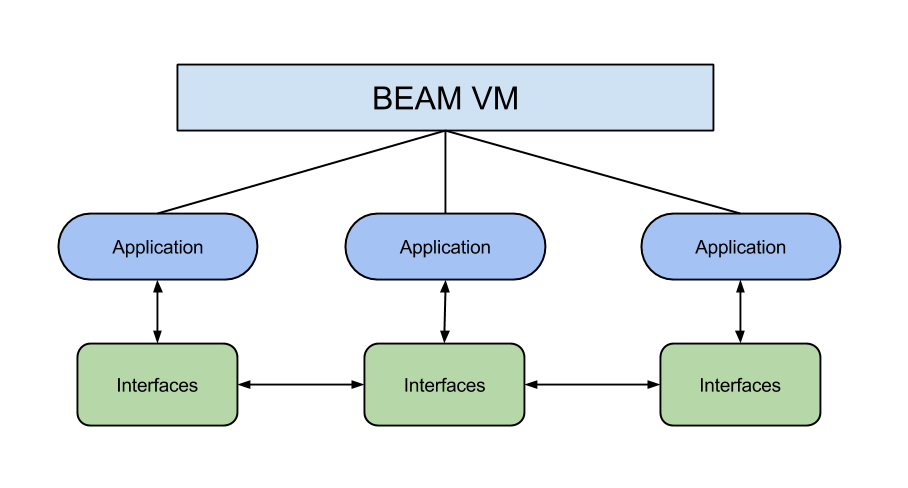
Задача: переместить все публичные функции приложения (функции, которые могут быть вызваны другим приложением) в отдельные модули. Например, в приложении datasets имеется специальный модуль интерфейса для функций приложения Fetchers:
defmodule Datasets.Interfaces.Fetchers do
alias Datasets.Fetchers
defdelegate zillow_data, to: Fetchers
defdelegate landsat_data, to: Fetchers
end
С помощью такой простой реализации можно делегировать вызовы функций соответствующему модулю. А в будущем, если будет решено перенести запущенное приложение datasets на другую ноду, этот модуль будет содержать основную часть логики взаимодействия.
В других приложениях можно сделать то же самое, просто переписав модуль Main.Zillow:
def rf_fit do
Datasets.Interfaces.Fetchers.zillow_data
|> Utils.Interfaces.PreProcessing.normalize_data
|> Models.Interfaces.Rf.fit_model
end
В общем, принцип таков: чтобы вызвать какую-либо функцию другого приложения, необходимо использовать модуль интерфейса.
Такой подход так же не усложняет разработку и тестирование, но привносит ряд простых правил, которые предотвращают сильную связность кода и выстаивают основу для будущего масштабирования.
Переход к распределённой системе
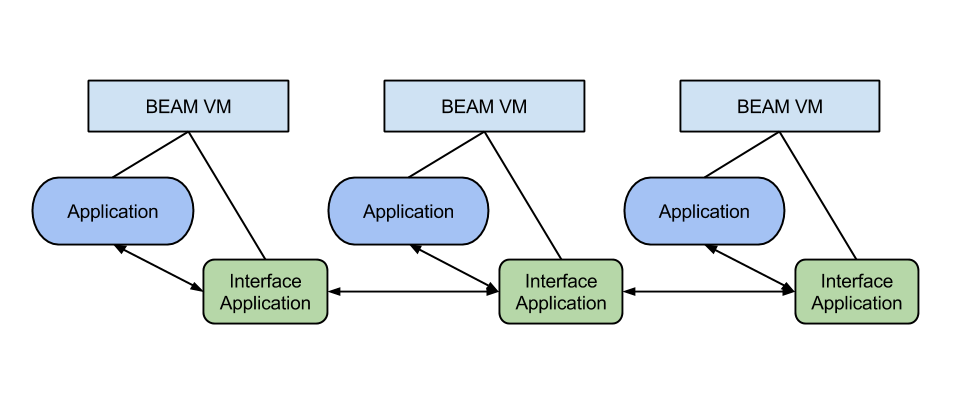
Предположим, обработка данных стала занимать слишком много времени, и было решено запускать приложение models на отдельной ноде. Получается, необходимо удалить {:models, in_umbrella: true} из списка зависимостей и запустить это приложение на другой ноде.
Запустив консоль (iex -S mix) из папки с главным приложением (main), можно увидеть, что доступ к модулям приложения models закрыт:
iex(1)> Models.Interfaces.Rf.fit_model(“data”)
** (UndefinedFunctionError) function Models.Interfaces.Rf.fit_model/1 is undefined (module Models.Interfaces.Rf is not available)
Код приложения models все ещё находится внутри зонтичного проекта, но он не запускается с главным предложением и находится вне доступа. Модули и функции приложения models существуют на другой ноде, которая запускает только его.
Но, как известно, виртуальная машина BEAM была создана для распределённых приложений, поэтому существует множество способов получить доступ к коду, запущенному на другой машине.
Модуль :rpc
Сравнительно просто запустить функцию на удалённой ноде с помощью модуля :rpc Эрланга. Для взаимодействия между нодами :rpc использует Erlang Distribution Protocol.
Можно даже провести небольшой эксперимент: запустить приложение main с помощью опции --sname main в одной вкладке терминала
iex --sname main -S mix
а проект models — в другой:
iex --sname models -S mix
Теперь можно что-нибудь посчитать:
iex(main@ip-192–168–1–150)1> :rpc.call(:”models@ip-192–168–1–150", Models.Interfaces.Rf, :fit_model, [“data”])
%{__struct__: Models.Rf.Coefficient, a: 1, b: 2, data: “data”}
Как же изменить текущий проект так, чтобы можно было воспользоваться приведённым выше способом?
Идея очень проста: нужно добавить в проект ещё одно приложение, реализующее логику взаимодействия, — models_interface.
models_interface/
config/
lib/
models_interface/
models_interface.ex
lm.ex
rf.ex
mix.ex
Вот такая небольшая правка предоставляет main доступ к функциям Models.Interface. Пару небольших модулей просто дублируют функции модулей Interfaces:
defmodule ModelsInterface.Rf do
def fit_model(data) do
ModelsInterface.remote_call(Models.Interfaces.Rf, :fit_model, [data])
end
end
Данный модуль просто вызывает функцию Models.Interfaces.Rf.fit_model/1, а реализация функции remote_call уже находится в модуле ModelsInterface:
defmodule ModelsInterface do
def remote_call(module, fun, args, env \\ Mix.env) do
do_remote_call({module, fun, args}, env)
end
def remote_node do
Application.get_env(:models_interface, :node)
end
defp do_remote_call({module, fun, args}, :test) do
apply(module, fun, args)
end
defp do_remote_call({module, fun, args}, _) do
:rpc.call(remote_node(), module, fun, args)
end
end
Данный модуль получает расположение ноды из конфигурации и осуществляет удалённый вызов процедуры. Обратите внимание на особую реализацию do_remote_call, которая позволяет упростить процесс тестирования, но об этом позже.
И последнее: нужно лишь заменить Models.Interfaces на ModelsInterface и всё готово! Только не забудьте добавить models_interface в список зависимостей главного приложения.
defp deps do
[
{:datasets, in_umbrella: true},
{:models, in_umbrella: true, only: [:test]},
{:models_interface, in_umbrella: true},
{:utils, in_umbrella: true},
{:espec, "1.4.6", only: :test}
]
end
Приложение models указано в зависимостях, но только в тестовом окружении. Это позволяет осуществлять прямые вызовы приложения в тестовом окружении.
Вот и всё. Теперь можно получить доступ к models через консоль iex:
iex(main@ip-192–168–1–150)1> ModelsInterface.Rf.fit_model(“data”)
%{__struct__: Models.Rf.Coefficient, a: 1, b: 2, data: “data”}
Итак, подведём итоги. Единственное изменение, которое необходимо было сделать, — это создание нового интерфейсного приложения. Весь код по-прежнему находится в одном месте, и все тесты пройдены.
##Распределённые задачи
Прямые удалённые вызовы процедур подойдут, если необходим простой синхронный интерфейс с другим приложением. Но когда дело касается запуска асинхронного кода на удалённой ноде, лучше всего использовать распределённые задачи.
Для динамического контроля задач в Эликсире используется специальный модуль Task.Supervisor. Он запускает супервизор внутри удалённого приложения и осуществляет надзор за задачами, исполняющими код. Воспользуемся распределёнными задачами, чтобы получить доступ к приложению datasets.
Прежде всего, добавим Task.Supervisor к списку потомков супервизора приложения datasets:
defmodule Datasets.Application do
@moduledoc false
use Application
import Supervisor.Spec
def start(_type, _args) do
children = [
supervisor(Task.Supervisor,
[[name: Datasets.Task.Supervisor]],
[restart: :temporary, shutdown: 10000])
]
opts = [strategy: :one_for_one, name: Datasets.Supervisor]
Supervisor.start_link(children, opts)
end
end
Модуль DatasetsInterface (отдельное интерфейсное приложение) выглядит так:
defmodule DatasetsInterface do
def spawn_task(module, fun, args, env \\ Mix.env) do
do_spawn_task({module, fun, args}, env)
end
defp do_spawn_task({module, fun, args}, :test) do
apply(module, fun, args)
end
defp do_spawn_task({module, fun, args}, _) do
Task.Supervisor.async(remote_supervisor(), module, fun, args)
|> Task.await
end
defp remote_supervisor do
{
Application.get_env(:datasets_interface, :task_supervisor),
Application.get_env(:datasets_interface, :node)
}
end
end
Будем использовать паттерн async/await. Отличие заключается в том, что задачи порождаются на удалённой ноде и контролируются удалённым супервизором, имя и расположение которого указаны в файле конфигурации:
config :datasets_interface,
task_supervisor: Datasets.Task.Supervisor,
node: :"models@ip-192-168-1-150"
И снова тот же трюк с тестовым окружением!
Другие протоколы
RPC и распределённые задачи — встроенные в Эрланг и Эликсир абстракции, позволяющие приложениям на Эликсире взаимодействовать без сериализации и десериализации. Но если требуется наладить связь с приложением, написанным на другом языке, то поможет более распространённый подход, такой как протокол HTTP.
В качестве примера реализуем простенький интерфейс HTTP для приложения utils. Как и в прошлый раз, сначала создаём новое приложение utils_interface:
Модуль UtilsInterface имеет похожую на ModelsInterface структуру, однако функция do_remote_call/2 выглядит так:
defp do_remote_call({module, fun, args}, _) do
{:ok, resp} = HTTPoison.post(remote_url(),
serialize({module, fun, args}))
deserialize(resp.body)
end
В данном примере будем использовать элементарную сериализацию Эрланга term_to_binary и binary_to_term:
defp serialize(term), do: :erlang.term_to_binary(term)
defp deserialize(data), do: :erlang.binary_to_term(data)
Проекту utils понадобится HTTP-сервер для прослушивания входящих запросов. Для этого воспользуемся cowboy и plug:
defp deps do
[
{:cowboy, "~> 1.0.0"},
{:plug, "~> 1.0"},
{:espec, "1.4.6", only: :test}
]
end
Так выглядит плаг, отвечающий за обработку запросов:
defmodule Utils.Interfaces.Plug do
use Plug.Router
plug :match
plug :dispatch
post "/remote" do
{:ok, body, conn} = Plug.Conn.read_body(conn)
{module, fun, args} = deserialize(body)
result = apply(module, fun, args)
send_resp(conn, 200, serialize(result))
end
end
Он попросту десериализует кортеж {module, fun, args}, вызывает функцию и отправляет результат обратно клиенту.
Не забудьте запустить плаг чепез сервер cowboy в приложении utils:
children = [
Plug.Adapters.Cowboy.child_spec(:http,
Utils.Interfaces.Plug, [], [port: 4001])
]
Обратите внимание, что вызывать функции напрямую из десериализованных данных не самый лучший ход. Здесь это сделано только в целях упрощения примера, на практике потребуется более продуманный метод.
Ограниченная конкурентность с poolboy
И последнее, о чём мы поговорим сегодня, поможет защитить приложение и его ресурсы от перегрузки. Представим, например, что приложение models использует слишком много памяти для подбора моделей. Соответственно, необходимо уменьшить количество клиентов, желающих получить доступ к этому приложению. Для этого на уровне интерфейса создадим ограниченный пул процессов-воркеров, используя библиотеку poolboy.
poolboy нужно запустить через супервизор приложения:
defmodule Models.Application do
use Application
def start(_type, _args) do
pool_options = [
name: {:local, Models.Interface},
worker_module: Models.Interfaces.Worker,
size: 5, max_overflow: 5]
children = [
:poolboy.child_spec(Models.Interface, pool_options, []),
]
opts = [strategy: :one_for_one, name: Models.Supervisor]
Supervisor.start_link(children, opts)
end
end
Видно, что у poolboy есть несколько опций: имя супервизора, модуль-воркер, размер пула и максимальная загрузка.
Модуль-воркер — простой GenServer, вызывающий соответствующую функцию:
defmodule Models.Interfaces.Worker do
use GenServer
def start_link(_opts) do
GenServer.start_link(__MODULE__, :ok, [])
end
def init(:ok), do: {:ok, %{}}
def handle_call({module, fun, args}, _from, state) do
result = apply(module, fun, args)
{:reply, result, state}
end
end
И последнее изменение касается модуля Models.Interfaces.Rf: вместо делегации функций, он будет порождать в пуле процесс-воркер:
defmodule Models.Interfaces.Rf do
def fit_model(data) do
with_poolboy({Models.Rf, :fit_model, [data]})
end
def with_poolboy(args) do
worker = :poolboy.checkout(Models.Interface)
result = GenServer.call(worker, args, :infinity)
:poolboy.checkin(Models.Interface, worker)
result
end
end
Теперь беспокоиться не о чем: приложение models сможет обработать только ограниченное число запросов.
Заключение
И в заключение пара рекомендаций:
-
С самого начала разработки думайте в сторону микросервисов. С зонтичным проектом на Эликсире это проще, чем вы думаете.
-
Для организации логики внутри приложений создавайте модули контекста и реализации.
-
Тщательно продумывайте интерфейсы приложений. Никаких прямых вызовов реализаций функций быть не должно.
-
Масштабируя проект в распределённую систему, помещайте логику взаимодействия в отдельное приложение. Для взаимодействия между приложениями, запущенными на BEAM, используйте Erlang Distribution Protocol.
Надеемся, подходы и абстракции, описанные в данной статье, помогут вам более грамотно работать на Эликсире.