Использование GenStage и Flow для создания системы рекомендаций товаров
Введение
Flow, подобно модулям Enum и Stream, позволяет разработчикам производить вычисления в коллекциях, однако с его помощью и с помощью GenStage вычисления могут выполняться параллельно.
Канонический пример, размещённый в сервисе GitHub, показывает, как с помощью Flow можно параллельно осуществить подсчёт количества слов в документе:
File.stream!("path/to/some/file")
|> Flow.from_enumerable()
|> Flow.flat_map(&String.split(&1, " "))
|> Flow.partition()
|> Flow.reduce(fn -> %{} end, fn word, acc ->
Map.update(acc, word, 1, & &1 + 1)
end)
|> Enum.to_list()Мне хотелось опробовать Flow в действии ещё с тех пор, когда Жозе Валим только представил концепции работы этого модуля на конференции "Elixir Conf 2016". У меня сразу же возникла мысль разработать инструмент для построения системы рекомендаций на основе отзывов большого количества людей (краудсорсинг). Так как это предполагает наличие задач с интенсивным вводом-выводом (HTTP-запросы) и операций с высокой вычислительной нагрузкой на CPU (например, анализ тональности текста), то параллельное исполнение и Flow – то, что нужно.
Так я и создал страницу Start learning Elixir.
Start learning Elixir
Start learning Elixir поможет найти лучшие ресурсы для изучения Elixir.
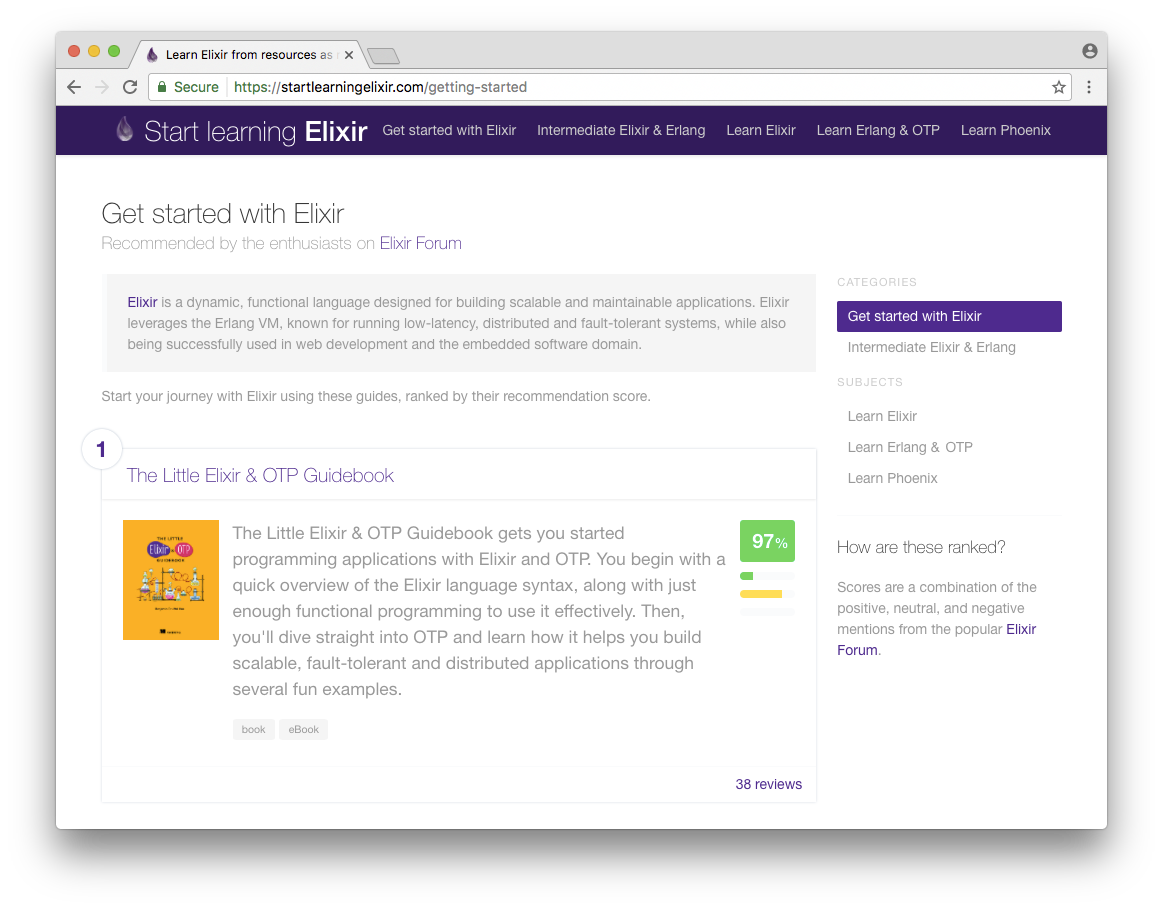
Краудсорсинг я использовал для того, чтобы найти и оценить подходящие учебные материалы: книги, электронные книги, видеоролики и обучающие курсы.
Алгоритм ранжирования основан на совокупности показателей популярности и результатов анализа тональности. Популярные материалы с высоким рейтингом имеют высокую оценку. Оценка – совокупность положительных, отрицательных и нейтральных отзывов пользователей известного форума об Elixir.
Создание инструмента рекомендации товаров
Разработанное мной зонтичное приложение (umbrella application) на Elixir состоит из трёх приложений:
-
indexer, осуществляющего выборку внешнего контента с помощью HTTP-запросов и упорядочивающего товары по рейтингу. -
recommendations, содержащего область Ecto schema и запросы: ресурсы, отзывы, оценки, авторы. -
web– фронтенд-части приложения в Phoenix, реализующей вывод рекомендованных товаров.
Flow используется в приложении indexer, где производятся все вычисления. Я набросал схему этапов конвейера, после чего разработал отдельный модуль для каждого этапа. Каждый этап разрабатывался и тестировался изолированно. Затем я объединил модули в единое целое и наладил их работу с помощью соответствующей функции Flow.
Высокоуровневый поток
В своём проекте разработки системы рекомендаций я использовал следующий непрерывный процесс:
- Создание списка рекомендованных ресурсов (подходящих книг, демо-роликов, сайтов, обучающих курсов) вручную.
-
Определение набора ключевых слов:
- "научиться", "книга", "книги", "электронные книги", "видео", "учебное пособие", "программирование на Elixir" и т. д.
- Поиск по ключевому слову на форуме об Elixir и получение списка тем.
-
Выборка постов по данной теме:
- парсинг содержимого поста (html-страницы);
-
удаление тегов
<aside/>и<code/>; -
разделение текста на предложения тегом
<p>; - извлечение текста.
- Поиск названий ресурсов в тексте.
- Выделение положительных, отрицательных и нейтральных отзывов с помощью анализа тональности текста.
- Объединение комментариев от одного и того же автора.
- Оценка ресурсов и начисление им рейтинга согласно частоте их упоминания и характера отзывов с использованием сглаживания Лапласа.
Получаем следующий код на Elixir (при участии Flow):
defmodule Learn.Indexer do
@moduledoc """
Index mentions of resources from an authoritative source.
"""
alias Learn.Indexer
alias Learn.Indexer.{
Mention,
Post,
Ranking,
Resource,
}
@doc """
Rank the given resources based on their mentions in topics matching the given keywords
"""
@spec rank(list(String.t), list(Resource.t)) :: list(Ranking.t)
def rank(keywords, resources, opts \\ []) do
keywords
|> Flow.from_enumerable()
|> Flow.flat_map(&Indexer.search(&1, opts))
|> Flow.uniq()
|> Flow.partition()
|> Flow.flat_map(&Indexer.list_posts(&1, opts))
|> Flow.partition(key: {:key, :id})
|> Flow.uniq_by(&(&1.id))
|> Flow.map(&Indexer.parse_html_content/1)
|> Flow.map(&Indexer.parse_sentences/1)
|> Flow.flat_map(&Indexer.extract_mentions(&1, resources))
|> Flow.map(&Indexer.sentiment_analysis/1)
|> Flow.partition(key: {:key, :resource})
|> Flow.group_by(&(&1.resource))
|> Flow.map(fn {resource, mentions} -> {resource, Indexer.aggregate_mentions_by_author(mentions)} end)
|> Flow.map(fn {resource, recommendations} -> Indexer.rank_recommendations(resource, recommendations) end)
|> Enum.to_list()
|> Enum.sort_by(&(&1.score), &>=/2)
end
endМожно заметить, что на некоторых этапах конвейера присутствуют дополнительные функции Flow.partition. Дополнительное разбиение позволяет убедиться в том, что данные передаются в тот же процесс, и минимизировать количество передаваемых сообщений. Для секционирования данных используется хэш-функция. Можно провести секционирование по функции, или по ключу-кортежу, это также необходимо при объединении или разделении каких-либо данных. При секционировании данные в каждой секции не будут накладываться друг на друга.
Подробнее об этапах конвейера Flow:
Поиск тем по ключевому слову
Форум об Elixir построен на платформе Discourse с общедоступным интерфейсом, предоставляющим данные в формате JSON. Для этого достаточно будет просто добавить .json к запросу.
Поисковый запрос по слову "book" (https://elixirforum.com/search?q=book) превратится в https://elixirforum.com/search.json?q=book. Таким же образом можно осуществлять поиск по отдельно взятым темам.
Я разработал простенький модуль ElixirForum, в котором для отправки HTTP-запросов использовал клиент-приложение HTTPoison, а для парсинга страницы – библиотеку Poison.
defmodule Learn.Indexer.Sources.ElixirForum do
use HTTPoison.Base
alias Learn.Indexer.Cache.HttpRequestCache
alias Learn.Indexer.Sources.ElixirForum
@endpoint "https://elixirforum.com"
defp process_url(path) do
@endpoint <> path
end
def process_response_body(body) do
body
|> Poison.decode!
end
def cached_request!(url, opts) do
HttpRequestCache.cached("elixirforum.com/" <> url, fn ->
rate_limit_access(fn ->
ElixirForum.get!(url).body
end, opts)
end)
end
defp rate_limit_access(request, opts \\ []) do
scale = Keyword.get(opts, :scale, 1_000)
limit = Keyword.get(opts, :limit, 1)
case ExRated.check_rate(@endpoint, scale, limit) do
{:ok, _} ->
request.()
{:error, _} ->
:timer.sleep(1_000)
rate_limit_access(request, opts)
end
end
defmodule Search do
@expected_fields ~w(posts topics)
def query(q, opts) do
"/search.json?" <> URI.encode_query(q: q)
|> ElixirForum.cached_request!(opts)
|> Map.take(@expected_fields)
|> Enum.map(fn({k, v}) -> {String.to_existing_atom(k), v} end)
end
end
endЧтобы поисковой робот работал надлежащим образом, на доступ к сайту с помощью ExRated поставлено ограничение по скорости так, что посылать можно лишь один запрос в секунду. Такое ограничение действует для всех запросов в данном модуле, независимо от вызывающего процесса, так как ExRated, как и GenServer, запускается с собственным состоянием.
Выглядит это так:
ElixirForum.Search.query("books", [scale: 1_000, limit: 1])Отклики кэшируются на диск, чтобы повторные запросы не повлияли на работу сайта.
defmodule Learn.Indexer.Cache.HttpRequestCache do
use GenServer
require Logger
defmodule State do
defstruct [
cache_dir: nil
]
end
def start_link(cache_dir) do
GenServer.start_link(__MODULE__, %State{cache_dir: cache_dir}, name: __MODULE__)
end
def init(%State{cache_dir: cache_dir} = state) do
File.mkdir_p!(cache_dir)
{:ok, state}
end
def cached(key, operation) do
case read(key) do
{:ok, value} -> value
{:error, :not_found} ->
value = operation.()
:ok = cache(key, value)
value
end
end
def read(key) do
GenServer.call(__MODULE__, {:read, key})
end
def cache(key, value) do
GenServer.call(__MODULE__, {:cache, key, value})
end
def handle_call({:read, key}, _from, %State{} = state) do
path = cached_path(key, state)
reply = case File.read(path) do
{:ok, data} -> {:ok, Poison.decode!(data)}
{:error, :enoent} -> {:error, :not_found}
{:error, _} = reply -> reply
end
{:reply, reply, state}
end
def handle_call({:cache, key, value}, _from, %State{} = state) do
path = cached_path(key, state)
File.write!(path, Poison.encode!(value), [:write])
{:reply, :ok, state}
end
defp cached_path(key, %State{cache_dir: cache_dir}) do
key = String.slice(key, 0, 255)
path = Path.join(cache_dir, key)
ensure_dir(path)
path
end
defp ensure_dir(path) do
path
|> Path.dirname()
|> File.mkdir_p!()
end
endМодуль кэша HTTP сконфигурирован в супервизоре приложения.
defmodule Learn.Indexer.Application do
@moduledoc false
use Application
def start(_type, _args) do
import Supervisor.Spec, warn: false
children = [
worker(Learn.Indexer.Cache.HttpRequestCache, ["fixture/http_cache"])
]
opts = [strategy: :one_for_one, name: Learn.Indexer.Supervisor]
Supervisor.start_link(children, opts)
end
endВо время тестирования поиска я снова воспользовался библиотекой ExVCR для записи HTTP-запросов и откликов и для повторного запуска с диска последующих тестов.
defmodule Learn.Indexer.Sources.ElixirForumTest do
use ExUnit.Case, async: false
use ExVCR.Mock, adapter: ExVCR.Adapter.Hackney
alias Learn.Indexer.Sources.ElixirForum
setup_all do
HTTPoison.start
:ok
end
describe "search" do
test "for \"books\"" do
use_cassette "elixirforum.com/search.json?&q=book", match_requests_on: [:query] do
response = ElixirForum.Search.query("book", [])
assert length(response[:posts]) > 0
assert length(response[:topics]) > 0
end
end
end
endПодробнее об этом можно почитать здесь.
Парсинг HTML-кода
Для парсинга HTML-кода и извлечения из него текста с помощью CSS-селекторов воспользуемся парсером Floki.
defmodule Learn.Indexer.Stages.ParseHtmlContent do
@moduledoc """
Parse the HTML post content into paragraphs of text.
"""
alias Learn.Indexer.{
Content,
Post,
}
def execute(%Post{content: content} = post) do
%Post{post |
content: parse_content_html(content),
}
end
defp parse_content_html(%Content{html: html} = content) do
paragraphs =
html
|> Floki.filter_out("aside")
|> Floki.filter_out("pre")
|> Floki.find("p")
|> Enum.map(&Floki.text/1)
|> Enum.flat_map(fn p -> String.split(p, "\n") end)
|> Enum.reject(fn p -> p == "" end)
%Content{content |
paragraphs: paragraphs,
}
end
endАбзацы определяются тегом <p>, а функция Floki.text/1 вытаскивает из них текст.
Парсинг предложений
Выделим отдельные предложения из текста поста. Для этого воспользуемся функцией Essence.Chunker.sentences из NLP-библиотеки essence.
defmodule Learn.Indexer.Stages.ParseSentences do
@moduledoc """
Parse the paragraphs of text into sentences.
"""
alias Learn.Indexer.{
Content,
Post,
}
def execute(%Post{content: content} = post) do
%Post{post |
content: parse_sentences(content),
}
end
# chunks the given paragraphs into sentences.
defp parse_sentences(%Content{paragraphs: paragraphs} = content) do
sentences =
paragraphs
|> Enum.map(&Essence.Chunker.sentences/1)
|> Enum.flat_map(fn sentences -> sentences end)
%Content{content |
sentences: sentences,
}
end
endИзвлечение названий товаров
Чтобы извлечь названия отдельных товаров:
-
Разобьём предложение на отдельные слова, написанные строчными буквами, с помощью функции
Essence.Tokenizer.tokenize:- “I recommend Elixir in Action” превратится в [“i, “recommend”, “elixir”, “in”, “action”]
-
Сделаем то же самое с названием товара:
- “Elixir in Action” превратится в [“elixir”, “in”, “action”]
-
С помощью функции
Enum.chunkпроизведём перебор расчленённых предложений, передав в неё длину искомого слова и шаг равный единице для учёта перекрытий, и осуществим поиск по заданному имени товара.
defp mentioned?(sentence, %Resource{name: name}) do
contains?(tokenize_downcase(sentence), tokenize_downcase(name))
end
def tokenize_downcase(text), do: text |> String.downcase |> Essence.Tokenizer.tokenize
defp contains?(source_tokens, search_tokens) do
source_tokens
|> Stream.chunk(length(search_tokens), 1)
|> Enum.any?(fn chunk -> chunk == search_tokens end)
endАнализ тональности
Для несложных анализов тональности я обычно использую систему Sentient. Она работает на основе списка слов AFINN-111, разделяя предложения на положительные, отрицательные и нейтральные на основе присутствия этих слов в тексте и их эмоциональной окраски.
AFINN – это список английских слов, отмеченных целыми числами согласно их коннотациям от минус пяти (отрицательная коннотация) до плюс пяти (положительная коннотация).
К примеру, текст "я рекомендую книгу "Elixir in Action" к прочтению" получит положительную оценку, поскольку слово "рекомендовать" отмечено значением числом +2. Список AFINN-111 содержит 2477 слов. Этот простейший алгоритм вполне адекватно оценивает тональность предложений.
defmodule Learn.Indexer.Stages.SentimentAnalysis do
@moduledoc """
Analyse the mention sentence for its sentiment (positive, neutral, or negative).
Uses the AFINN-111 word list.
"""
alias Learn.Indexer.{
Mention,
}
@spec execute(Mention.t) :: Mention.t
def execute(%Mention{} = mention) do
%Mention{mention |
sentiment_score: sentiment(mention),
}
end
@override_words %{"free" => 0}
defp sentiment(%Mention{sentence: sentence}) do
Sentient.analyze(sentence, @override_words)
end
endОценка тональности предложения, содержащего название товара, добавляется к общей оценке этого товара.
Рекомендации (оценки)
Общая оценка определяется заново каждый раз, когда в тексте было найдено название того или иного товара и была проведена оценка тональности.
Чтобы при оценке отделить соотношение положительных/отрицательных отзывов от малого количества отзывов по товару, воспользуемся формулой сглаживания Лапласа:
score = (upvotes + α) / (upvotes + downvotes + β)Например, при α = 1 и β = 2 товар без голосов получит оценку 0,5.
По каждому товару могут быть положительные, отрицательные и нейтральные отзывы. В моём случае каждый нейтральный комментарий получает оценку +1, а каждый положительный получает +2.
defmodule Learn.Indexer.Stages.RankRecommendations do
@moduledoc """
Combine recommendations for the same resource into a single ranking and score
"""
alias Learn.Indexer.{
Ranking,
Recommendation,
Resource,
}
@spec execute(Resource.t, list(Recommendation.t)) :: Ranking.t
def execute(resource, recommendations) do
%Ranking{
resource: resource,
recommendations: recommendations,
score: calculate_score(recommendations),
}
end
# calculate score by using Laplace smoothing on positive, neutral and negative mentions
defp calculate_score([]), do: 0
defp calculate_score(recommendations) do
recommendations
|> Enum.reduce({0, 0, 0}, &Recommendation.score/2)
|> score
end
defp score({negative, neutral, positive}) do
upvotes = neutral + (positive * 2)
downvotes = negative
(upvotes + 1) / (upvotes + downvotes + 2)
end
endСуществует исследование о применении сглаживания Лапласа для "предоставления наиболее верного решения проблемы ранжирования информации на основе оценок пользователей в веб-приложениях".
Рекомендации (краудсорсинг)
Объединяя отдельные этапы в единый конвейер с помощью Flow, можно оценить любой товар по отзывам на него.
def index_mentions(keywords, resources, opts \\ []) do
keywords
|> Learn.Indexer.rank(resources, opts)
|> record_rankings(resources)
endEcto сохраняет их в базу данных PostgreSQL. Отобразить товары, упорядоченные по рейтингу, поможет Ecto-запрос, представленный ниже. Товары можно отсортировать по языку программирования или по уровню знания языка и классифицировать их по этим признакам на сайте.
defmodule Learn.Recommendations.Queries.RecommendedResources do
import Ecto.Query
alias Learn.Recommendations.{
Resource,
Score,
}
def new do
from r in Resource,
left_join: s in assoc(r, :score),
order_by: [asc: s.rank, asc: r.title],
preload: [:score]
end
def by_experience(query, level) do
from [r, s] in query,
where: r.experience_level == ^level
end
def by_language(query, language) do
from [r, s] in query,
where: r.programming_language == ^language
end
endКонтроллер Phoenix составляет запрос и осуществляет выборку подходящих ресурсов с помощью функции Repo.all/2:
defmodule Learn.Web.ResourceController do
use Learn.Web.Web, :controller
alias Learn.Recommendations.Repo,
alias Learn.Recommendations.Queries.RecommendedResources
def index(conn, _params) do
resources =
RecommendedResources.new
|> RecommendedResources.by_experience("beginner")
|> RecommendedResources.by_language("Elixir")
|> Repo.all()
render conn, "index.html", resources: resources
end
endЗаключение
Рассмотренное приложение – пример использования Flow для построения вычислительного конвейера с параллельным выполнением операций для решения реальных задач. Предполагалось, что применение упрощённого алгоритма построения системы рекомендаций не имеет особого смысла. Однако, взглянув на конечные результаты, можно констатировать обратное: популярные ресурсы с высоким рейтингом занимают положение на вершине списка. Значение популярности, формирующееся из комментариев пользователей и результатов анализа тональности, может быть использовано для ранжирования товаров.
Недавно я добавил на сайт отслеживание активности пользователей, чтобы затем использовать эти значения для оценки. Таким образом, наиболее часто просматриваемые ресурсы имеют более высокий рейтинг. Возможно, в скором времени на сайте появится ещё и механизм обратной связи, чтобы пользователи могли отмечать ошибочные отзывы и оставлять свои.
Свяжитесь со мной, если у вас возникли какие-либо вопросы и предложения.
Оптимизация
Я был приятно удивлён алгоритмом оптимизации моего конвейера Flow, представленным Таймоном Тобольски, который написал две чудесные статьи на эту тему.
- Оптимизация обработки данных с помощью GenStage/Flow в Elixir
- Измерения и визуализация работы GenStage/Flow с помощью GnuPlot
Взяв разработанный им модуль Progress и исходный код GnuPlot, я смог провести оптимизацию своего конвейера и визуализировать результаты его работы.
Отслеживание прогресса
Модуль Learn.Progress целиком взят из статьи Таймона.
defmodule Learn.Progress do
@moduledoc """
Progress stats collector, courtesy of http://teamon.eu/2016/measuring-visualizing-genstage-flow-with-gnuplot/
"""
use GenServer
@timeres :millisecond
# Progress.start_link [:a, :b, :c]
def start_link(scopes \\ []) do
GenServer.start_link(__MODULE__, scopes, name: __MODULE__)
end
def stop do
GenServer.stop(__MODULE__)
end
# increment counter for given scope by `n`
# Progress.incr(:my_scope)
# Progress.incr(:my_scope, 10)
def incr(scope, n \\ 1) do
GenServer.cast __MODULE__, {:incr, scope, n}
end
def init(scopes) do
File.mkdir_p!("fixture/trace")
# open "progress-{scope}.log" file for every scope
files = Enum.map(scopes, fn scope ->
{scope, File.open!("fixture/trace/progress-#{scope}.log", [:write])}
end)
# keep current counter for every scope
counts = Enum.map(scopes, fn scope -> {scope, 0} end)
# save current time
time = :os.system_time(@timeres)
# write first data point for every scope with current time and value 0
# this helps to keep the graph starting nicely at (0,0) point
Enum.each(files, fn {_, io} -> write(io, time, 0) end)
{:ok, {time, files, counts}}
end
def handle_cast({:incr, scope, n}, {time, files, counts}) do
# update counter
{value, counts} = Keyword.get_and_update!(counts, scope, &({&1+n, &1+n}))
# write new data point
write(files[scope], time, value)
{:noreply, {time, files, counts}}
end
defp write(file, time, value) do
time = :os.system_time(@timeres) - time
IO.write(file, "#{time}\t#{value}\n")
end
endЯ также воспользовался библиотекой decorator Арджана Шерпениссе, чтобы добавить отслеживание прогресса в функцию каждого этапа конвейера, поставив перед объявлением каждой функции @decorate progress.
defmodule Learn.Indexer do
@moduledoc """
Index mentions of resources from an authoritative source.
"""
use Learn.ProgressDecorator
@doc """
Search for topics matching a given query
"""
@decorate progress
def search(query, opts \\ []), do: SearchKeyword.execute(query, opts)
endДекоратор увеличивает счётчик метода после его выполнения. Счётчик увеличивается на количество элементов в возвращаемом функцией списке или на единицу, если список не был возвращён.
defmodule Learn.ProgressDecorator do
use Decorator.Define, [progress: 0]
alias Learn.Progress
def progress(body, context) do
quote do
reply = unquote(body)
case reply do
list when is_list(list) -> Progress.incr(unquote(context.name), length(list))
_ -> Progress.incr(unquote(context.name), 1)
end
reply
end
end
endФункция Learn.Indexer.rank/3 передаёт в процесс имя каждого этапа перед выполнением потока. После этого она останавливает процесс, проверяет, чтобы файлы журналов были созданы и закрыты.
defmodule Learn.Indexer do
@moduledoc """
Index mentions of resources from an authoritative source.
"""
@doc """
Rank the given resources based on their mentions in topics matching the given keywords
"""
@spec rank(list(String.t), list(Resource.t)) :: list(Ranking.t)
def rank(keywords, resources, opts \\ []) do
Progress.start_link([
:search,
:list_posts,
:parse_html_content,
:parse_sentences,
:extract_mentions,
:sentiment_analysis,
:aggregate_mentions_by_author,
:rank_recommendations,
])
rankings =
keywords
|> Flow.from_enumerable(max_demand: 1, stages: 1)
|> Flow.flat_map(&Indexer.search(&1, opts))
|> Flow.uniq()
|> Flow.partition(max_demand: 5)
|> Flow.flat_map(&Indexer.list_posts(&1, opts))
|> Flow.partition(key: {:key, :id}, max_demand: 5)
|> Flow.uniq_by(&(&1.id))
|> Flow.map(&Indexer.parse_html_content/1)
|> Flow.map(&Indexer.parse_sentences/1)
|> Flow.flat_map(&Indexer.extract_mentions(&1, resources))
|> Flow.map(&Indexer.sentiment_analysis/1)
|> Flow.partition(key: {:key, :resource}, max_demand: 5)
|> Flow.group_by(&(&1.resource))
|> Flow.map(fn {resource, mentions} -> {resource, Indexer.aggregate_mentions_by_author(mentions)} end)
|> Flow.map(fn {resource, recommendations} -> Indexer.rank_recommendations(resource, recommendations) end)
|> Enum.to_list()
|> Enum.sort_by(&(&1.score), &>=/2)
Progress.stop()
rankings
end
endВизуализация потока
После запуска индексатора, в котором функции этапов были отмечены тегом @progress, я построил графики "до" и "после".
Изначальный поток
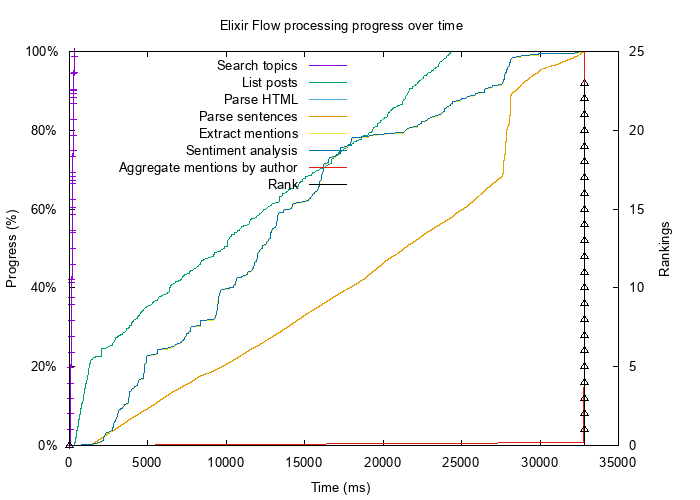
В первоначальной версии приложения поток запускался в течение 33 секунд. HTTP-кэш заполнен, внешние запросы отсутствуют.
Поток после оптимизации
Я изменил опции max_demand и stages для некоторых этапов Flow, как показано выше. Это позволило сократить время запуска потока с 33 секунд до 26.
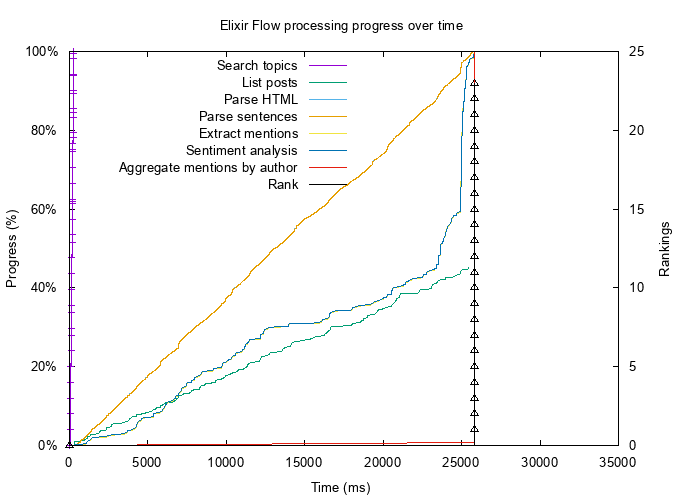
Графики были построены с помощью следующего кода (GnuPlot): Они показывают прогресс выполнения каждого этапа в процентах. Полученные рекомендации, упорядоченные по рейтингу, показаны на отдельной оси y.
# plot.gp
set terminal png font "Arial,10" size 700,500
set output "progress.png"
set title "Elixir Flow processing progress over time"
set xlabel "Time (ms)"
set ylabel "Progress (%)"
set y2label "Rankings"
set ytics nomirror
set yrange [0:100]
set format y '%2.0f%%'
set y2tics
set key top left # put labels in top-left corner
# limit x range to 35.000 ms instead of dynamic one - needed when generating graphs that will be later compared visually
set xrange [0:35000]
plot "trace/progress-search.log" using ($1):($2/1249*100) with steps axes x1y1 ls 1 title "Search topics",\
"trace/progress-search.log" using ($1):($2/1249*100) with points axes x1y1 ls 1 notitle,\
"trace/progress-list_posts.log" using ($1):($2/14974*100) with lines axes x1y1 ls 2 title "List posts",\
"trace/progress-parse_html_content.log" using ($1):($2/6780*100) with lines axes x1y1 ls 3 title "Parse HTML",\
"trace/progress-parse_sentences.log" using ($1):($2/6780*100) with lines axes x1y1 ls 4 title "Parse sentences",\
"trace/progress-extract_mentions.log" using ($1):($2/515*100) with lines axes x1y1 ls 5 title "Extract mentions",\
"trace/progress-sentiment_analysis.log" using ($1):($2/515*100) with lines axes x1y1 ls 6 title "Sentiment analysis",\
"trace/progress-aggregate_mentions_by_author.log" using ($1):($2/314*100) with lines axes x1y1 ls 7 title "Aggregate mentions by author",\
"trace/progress-rank_recommendations.log" with steps axes x1y2 ls 8 title "Rank",\
"trace/progress-rank_recommendations.log" with points axes x1y2 ls 8 notitle