Списки ввода-вывода в Elixir. Часть 2: применение в Phoenix
В предыдущей части мы рассмотрели, как использование списков ввода-вывода в Elixir упрощает работу над реализацией вывода данных и уменьшает расход памяти.
Это отличное решение для создания файлов, но оно едва ли подойдет для веб-приложений. Любая веб-страница содержит динамические элементы: имя текущего пользователя, список недавних постов или изображение товаров в корзине.
Но эти динамические фрагменты оборачиваются в разметку, которая всегда выглядит одинаково: например, каждый товар помещается в <div class="product">. А меню, шапка и подвал, скорее всего, содержат одни и те же большие куски HTML-кода.
Предположим, имеется шаблон с именем users/index.html.eex, который выглядит так:
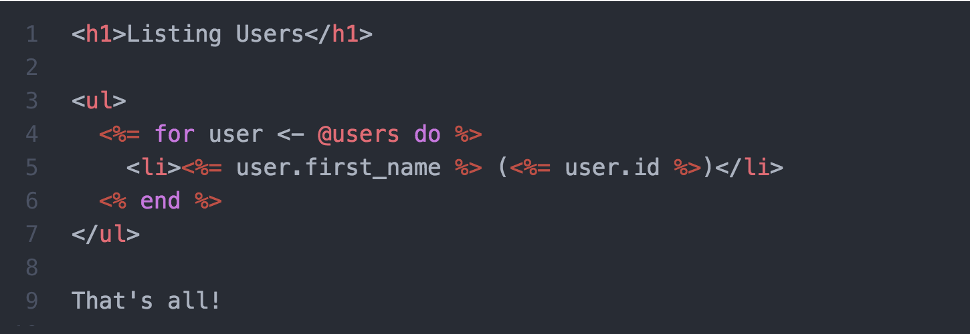
Эти строки понадобятся нам снова и снова, а выделенный текст вообще никогда не меняется:
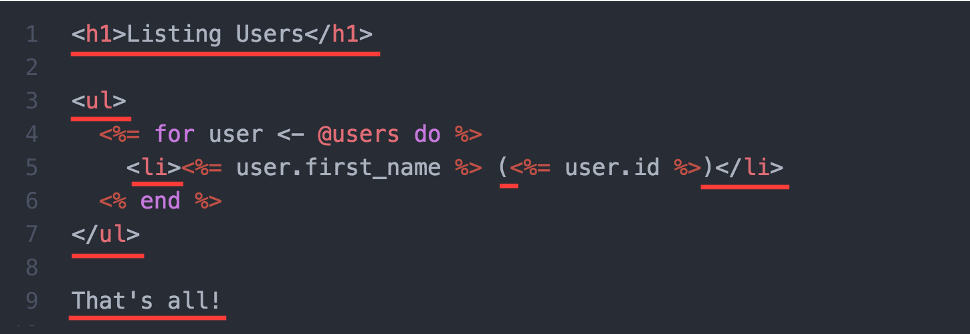
Большинство веб-фреймворков осуществляют конкатенацию статической разметки и динамических данных в одну большую строку ответа. Реализовать такую конкатенацию не так то просто, да и сборщику мусора при этом придётся хорошенько поработать.
Вместо всего этого Phoenix:
-
загружает все шаблоны из директории шаблонов на этапе компиляции;
-
находит среди них
users/index.html.eex; -
использует EEx для компиляции шаблона в функцию вместе с его макетом и фрагментами;
-
приказывает EEx сделать так, чтобы эта функция создавала и возвращала не строки, а списки ввода-вывода;
-
хранит функцию рендеринга шаблона в виде
UsersView.render("index.html«, assigns);
Созданная функция будет выглядеть примерно так:
defmodule MyApp.SomeView do
defp(index.html(var!(assigns))) do
_ = var!(assigns)
{:safe, [(
tmp1 = ["" | "<h1>Listing Users</h1>\n\n<ul>\n "]
[tmp1 | case(for(user <- Phoenix.HTML.Engine.fetch_assign(var!(assigns), :users)) do
{:safe, [(
tmp1 = [(
tmp1 = ["" | "\n <li> "]
[tmp1 | case(user.first_name()) do
{:safe, data} ->
data
bin when is_binary(bin) ->
Plug.HTML.html_escape(bin)
other ->
Phoenix.HTML.Safe.to_iodata(other)
end]
) | " ("]
[tmp1 | case(user.id()) do
{:safe, data} ->
data
bin when is_binary(bin) ->
Plug.HTML.html_escape(bin)
other ->
Phoenix.HTML.Safe.to_iodata(other)
end]
) | ")</li>\n "]}
end) do
{:safe, data} ->
data
bin when is_binary(bin) ->
Plug.HTML.html_escape(bin)
other ->
Phoenix.HTML.Safe.to_iodata(other)
end]
) | "\n</ul>\n\nThat's all!\n"]}
end
def(render("index.html", assigns)) do
index.html(assigns)
end
endОтметим, что в этой функции присутствуют строковые литералы вроде <h1>Listing Users</h1>\n\n<ul>\n и \n <li>. Это одни и те же иммутабельные строки, которые хранятся в одних и тех же ячейках памяти и запрос за запросом появляются в возвращаемом списке ввода-вывода.
После запуска функция возвратит такой список ввода-вывода:
[[["" | "<h1>Listing Users</h1>\n\n<ul>\n "],
[[[[["" | "\n <li>"] | "Jane"] | " ("] | "1"] | ")</li>\n "],
[[[[["" | "\n <li>"] | "Joe"] | " ("] | "2"] | ")</li>\n "]] |
"\n</ul>\n\nThat's all!\n"]Странный список, не находите? Всё потому, что это «неправильный» список.
Списки обычно составляются путём добавления новых элементов в конец:
list = [] # => []
list = ["C" | list] # => ["C"]
list = ["B" | list] # => ["B", "C"]
list = ["A" | list] # => ["A", "B", "C"]Каждый элемент этого списка сам по себе тоже представляет собой список, первый элемент которого — указатель на строку, а последний элемент — указатель на следующий список. Последний список пустой (в примере его нет). Как же много списков!
Можно ещё сделать так:
list = ["A" | "B"] # => ["A" | "B"]Этот список «неправильный», так как его первый элемент указывает на «A», а последний указывает не на список, а на «B».
Многие функции, ожидающие передачи списков, будут прерваны при получении «неправильного» списка, поэтому обычно их лучше вообще не использовать. Но так как единственное, что мы сегодня будем делать с этими списками, — это оборачивать их в другие списки, а затем записывать их в сокет, «неправильные» списки позволят избежать выделения памяти под такое большое количество данных.
Что ж, идём дальше.
А дальше как раз происходит самое интересное: список ввода-вывода передаётся процессу веб-сервера, который выводит его пользователю, вызывая в сетевом сокете функцию writev. Ответ на запрос формируется в окончательном виде только в буфере сокета.
Напомню, что минимальное требование для отправки ответа — скопировать каждый байт ответа в сокет. Это всё, что делает Phoenix при реализации выбранного способа рендеринга представлений.
Кэширование
Описанный выше способ построения ответов обладает ещё одним преимуществом. Помните тот пример шаблона, который содержит строки, повторяющиеся в последующем коде снова и снова?
Мы уже видели, как функция, которую Phoenix компилирует для рендеринга этого шаблона, всё время использует одни и те же строки, просто добавляя в список ввода-вывода необходимые динамические компоненты. Фактически это не что иное, как кэширование представлений.
Наверняка вы уже имели дело с веб-фреймворками, производящими рендеринг представлений при помощи конкатенации. Они пытаются компенсировать низкую скорость своей работы наличием различных способов кэширования представлений и фрагментов. Вместе с тем они вынудят вас заняться поиском решения одной из сложнейших проблем информатики — проблемы инвалидации кэша. Следует учитывать, что контент веб-страницы постоянно меняется.
К примеру, пост блога может обновиться в базе данных. Проблему можно решить, поставив ограничение по времени (кэшировать нужный фрагмент поста в течение одного часа) или привязав кэш представления к состоянию базы данных. Например, HTML-код поста блога и комментариев к нему можно поместить в кэш, но тогда, если в пост или комментарии будут внесены изменения, изменится имя автора поста или имя автора комментария, представление необходимо будет рендерить снова. Такие же правила актуальны и для кэширования матрёшкой в Rails.
Нужно также иметь в виду, что элементы страницы для каждого пользователя могут быть разными. Например, адрес электронной почты пользователя или список рекомендованных товаров. Эту проблему можно решить путём создания ключей кэша отдельно для каждого пользователя, как это показано в , или путём кэширования некой общей версии и добавления персонализированного контента после загрузки страницы с помощью Javascript, как сделано в примере. Ну или попробовать вообще обойтись без кэширования.
В любом случае только вам решать, какие части представления стоит кэшировать и при каких обстоятельствах кэш будет считаться валидным. Чем чаще обновляется контент и чем больше он содержит персонализированной информации, тем больше места он занимает в хранилище кэша.
А я разве не говорил, что вам потребуется хранилище кэша? Вам самим придётся решить, где выделить место для кэша: в оперативной памяти, в файловой системе или во внешней базе данных, а потом разбираться со всеми последствиями своего решения.
Не хочу показаться грубым, но все грамотные разработчики прикладывают немало усилий, чтобы кэширование представлений происходило легко и удобно, но даже при существующем множестве решений здесь всё ещё есть над чем поработать.
Phoenix же, напротив, использует простую и универсальную модель кэширования представлений: кэшируются только статические элементы шаблона, а при изменении файла шаблона данные в кэше аннулируются. Вот и вся схема.
Так как динамические элементы представления (например, список заголовков постов блога в базе данных) не кэшируются, то нужно передать эти данные функциям представления во время рендеринга. Если запросы к базе данных — узкое место в производительности приложения, то можно просто кэшировать результаты. Воспользуйтесь, к примеру, , и специальный процесс будет периодически обновлять результаты. Но это уже никак не связано с шаблонами. Рендеринг представлений в Phoenix происходит так быстро, что задумываться о кэшировании полученных страниц просто нет времени.
Дисклеймер
Прежде чем перейти к выводам, я хотел бы немного поговорить о системных вызовах.
В предыдущей части статьи было показано, как виртуальная машина BEAM объединяет короткие строки (длиной менее 64 байт), помещая их в аргументы функции writev. Если провести трассировку Phoenix-приложения, то вряд можно увидеть, чтобы каждый тег <li> передавался в функцию writev в качестве отдельного аргумента. Но writev всё же используется в сокете.
Вот мой пример трассировки Phoenix-приложения, в шаблонах которого присутствуют очень длинные строки:

Две очень длинные строки, которые я выделил синим, повторяются в шаблоне несколько раз. При записи ответа в сокет, сервер Cowboy всё время ссылается в памяти на одни и те же строки. Строка, выделенная красным, состоит из открывающего HTML-тега и неких неизменяемых данных. На снимке экрана она встречается только один раз, хотя на самом деле в последующих запросах она считывалась снова и снова с одного из того же адреса памяти.
Но независимо от того, как BEAM записывает ответы Phoenix в сокет, такой способ выигрывает по скорости и эффективности расхода ресурсов.
Так что в следующий раз, когда Phoenix отрендерит страницу меньше чем за миллисекунду, подумайте о волшебном списке ввода-вывода, благодаря которому это становится возможным.