Списки ввода-вывода в Elixir. Часть 3: преимущества использования
В предыдущих статьях (первая, вторая) было показано, как с помощью списков ввода-вывода сделать код более эффективным.
В его примере список ввода-вывода создаётся при помощи Enum.map:
users = [%{name: "Amy"}, %{name: "Joe"}]
response = Enum.map(users, fn (user) ->
["<li>", user.name, "</li>"]
end)
IO.puts responseПовторяющиеся строки заносятся в память только один раз. Создание одинаковых строк с помощью интерполяции ("<li>#{user.name}</li>") или конкатенации (<li>" <> user.name <> "</li>") потребует дополнительных операций по выделению памяти и копированию данных. В результате память будет использоваться менее эффективно, а у сборщика мусора появится много лишней работы.
Использование списков
Ознакомившись со статьёй, я непременно решил воспользоваться списками ввода-вывода в одном из своих открытых проектов на Elixir. Речь пойдёт о PostgreSQL для сохранности данных. Конструирование SQL-оператора для вставки большого количества событий осуществляется путём конкатенации и интерполяции строк. Так как в конечной строке получается очень много повторов, то здесь как раз и пригодится список ввода-вывода.
Поддержка Postgrex запросов со списками ввода-вывода
В EventStore используется в качестве драйвера для взаимодействия с PostgreSQL. Таким образом, SQL-оператор insert превращается в функцию Postgrex.query/4. В документации к функции query/4 сказано, что её аргументом должны выступать данные ввода-вывода. Получается, что этим аргументом может быть и список ввода-вывода.
Итак, я подтверждаю, что запросы к PostgreSQL, состоящие из строки или списка ввода-вывода, выступающих в качестве SQL-оператора, при запуске кода в интерактивной консоли iex отлично справляются со своими задачами.
$ iex -S mix
Erlang/OTP 19 [erts-8.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
Interactive Elixir (1.3.3) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> storage_config = Application.get_env(:eventstore, EventStore.Storage)
[username: "postgres", password: "postgres", database: "eventstore_dev",
hostname: "localhost", pool_size: 10,
extensions: [{Postgrex.Extensions.Calendar, []}]]
iex(2)> {:ok, conn} = Postgrex.start_link(storage_config)
{:ok, #PID<0.208.0>}
iex(3)> Postgrex.query!(conn, "select * from events;", [])
%Postgrex.Result{columns: ["event_id", "stream_id", "stream_version",
"event_type", "correlation_id", "data", "metadata", "created_at"],
command: :select, connection_id: 16993, num_rows: 0, rows: []}
iex(4)> Postgrex.query!(conn, ["select *", "from events", ";"], [])
%Postgrex.Result{columns: ["event_id", "stream_id", "stream_version",
"event_type", "correlation_id", "data", "metadata", "created_at"],
command: :select, connection_id: 16993, num_rows: 0, rows: []}Реализация
Изменения в EventStore я внёс только в тело функции EventStore.Sql.Statements.create_events/1. Изначально SQL-оператор конструировался тем, что несколько событий помещались в insert с помощью интерполяции и конкатенации строк.
def create_events(number_of_events \\ 1) do
insert = "INSERT INTO events (event_id, stream_id, stream_version, correlation_id, event_type, data, metadata, created_at) VALUES"
params =
1..number_of_events
|> Enum.map(fn event_number ->
index = (event_number - 1) * 8
"($#{index + 1}, $#{index + 2}, $#{index + 3}, $#{index + 4}, $#{index + 5}, $#{index + 6}, $#{index + 7}, $#{index + 8})"
end)
|> Enum.join(",")
insert <> " " <> params <> ";"
endТеперь я сделал так, чтобы оператор составлялся с использованием вложенных списков ввода-вывода. Добавление элемента в список путём вложения – операция, которая выполнится за время O(1) и не потребует копирования данных.
def create_events(number_of_events \\ 1) do
insert = ["INSERT INTO events (event_id, stream_id, stream_version, correlation_id, event_type, data, metadata, created_at) VALUES"]
params =
1..number_of_events
|> Enum.map(fn event_number ->
index = (event_number - 1) * 8
event_params = [
"($",
Integer.to_string(index + 1), ", $",
Integer.to_string(index + 2), ", $",
Integer.to_string(index + 3), ", $",
Integer.to_string(index + 4), ", $",
Integer.to_string(index + 5), ", $",
Integer.to_string(index + 6), ", $",
Integer.to_string(index + 7), ", $",
Integer.to_string(index + 8), ")"
]
if event_number == number_of_events do
event_params
else
[event_params, ","]
end
end)
[insert, " ", params, ";"]
endЧтобы убедиться, что использование списков приносит свои плоды, я провёл несколько юнит-тестов.
Тестирование
В EventStore имеется тестовый набор бенчмарков, использующих Benchfella – инструмент для микробенчмаркинга в Elixir. Benchfella позволяет выбрать бенчмарк, запустить его несколько раз, сравнить результаты и представить их в виде графика.
Существующие бенчмарки покрывают большинство основных сценариев использования EventStore, то есть запись событий в поток и считывание их из потока. Набор бенчмарков включает и отдельные тесты для одного, 10 или 100 конкурентных процессов чтения/записи.
Ниже приведён пример бенчмарка для вставки 100 событий (сгенерированных до запуска теста) в EventStore.
defmodule AppendEventsBench do
use Benchfella
alias EventStore.EventFactory
alias EventStore.Storage
setup_all do
Application.ensure_all_started(:eventstore)
end
before_each_bench(store) do
{:ok, EventFactory.create_events(100)}
end
bench "append events, single writer" do
EventStore.append_to_stream(UUID.uuid4, 0, bench_context)
end
endЯ сравнил время выполнения операций до и после внесения изменений, используя EventStore benchmark suite, чтобы убедиться в том, что производительность действительно стала выше.
Запуск бенчмарков
Чтобы обеспечить чистое окружение, перед запуском тестов нужно удалить и заново создать базу данных PostgreSQL.
MIX_ENV=bench mix do es.reset, app.start, benchРезультаты бенчмарка ДО
## AppendEventsBench
benchmark name iterations average time
append events, single writer 100 15787.46 µs/op
append events, 10 concurrent writers 10 137400.10 µs/op
append events, 100 concurrent writers 1 1495547.00 µs/op
## ReadEventsBench
benchmark name iterations average time
read events, single reader 1000 2151.71 µs/op
read events, 10 concurrent readers 100 20172.47 µs/op
read events, 100 concurrent readers 10 202203.20 µs/opРезультат бенчмарка ПОСЛЕ
## AppendEventsBench
benchmark name iterations average time
append events, single writer 100 12239.92 µs/op
append events, 10 concurrent writers 10 108868.50 µs/op
append events, 100 concurrent writers 1 1116299.00 µs/op
## ReadEventsBench
benchmark name iterations average time
read events, single reader 1000 1928.22 µs/op
read events, 10 concurrent readers 100 20102.93 µs/op
read events, 100 concurrent readers 10 201094.80 µs/opСравнение результатов бенчмарков
В Benchfella имеется инструмент, который позволяет сравнить результаты двух последних запусков. Он показывает, как изменилась производительность между двумя запусками теста.
$ MIX_ENV=bench mix bench.cmp
bench/snapshots/2016-10-28_12-33-28.snapshot vs
bench/snapshots/2016-10-28_12-34-12.snapshot
## AppendEventsBench
append events, 100 concurrent writers 0.75
append events, single writer 0.78
append events, 10 concurrent writers 0.79
## ReadEventsBench
read events, single reader 0.9
read events, 100 concurrent readers 0.99
read events, 10 concurrent readers 1.0Можно видеть, что благодаря использованию списков ввода-вывода производительность возросла. После рефакторинга кода события добавляются в базу данных на 20-25% быстрее. Чтение событий происходит с прежней скоростью.
Сравнительный график
С помощью Benchfella построить не составит труда.
$ MIX_ENV=bench mix bench.graph
Wrote bench/graphs/index.htmlЛинейная шкала
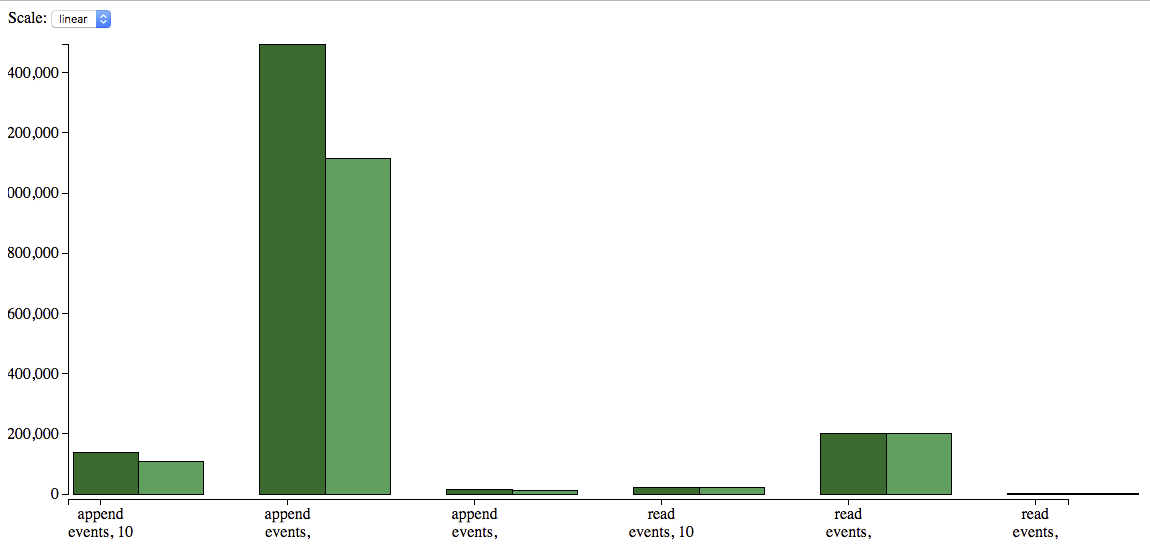
Логарифмическая шкала
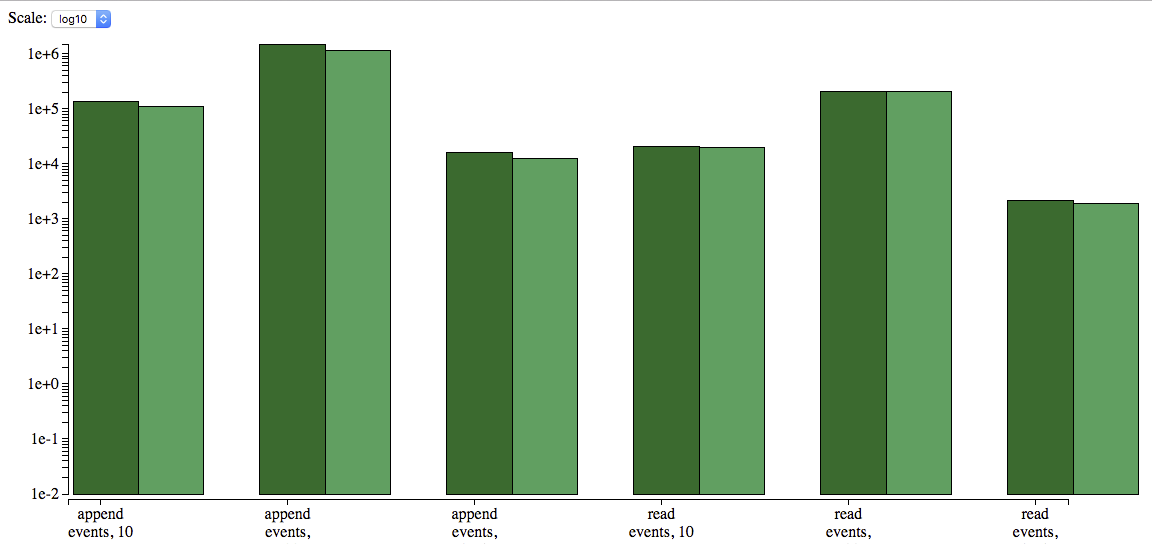
Выводы
Использование списка ввода-вывода положительно сказывается на производительности. Если вы планируете организовать вывод данных и записать их в файл, то вот небольшой совет: забудьте о конкатенации. Воспользуйтесь списком ввода-вывода.