Оптимизация обработки данных с помощью GenStage/Flow
Существует множество задач, которые можно решить с помощью GenStage/Flow.
Недавно мне довелось работать над одной из подобных задач: необходимо было осуществить выборку записей из базы данных PostgreSQL, загрузить связанные с этими записями файлы из Amazon S3, извлечь из файлов текст и провести его индексацию в ElasticSearch.
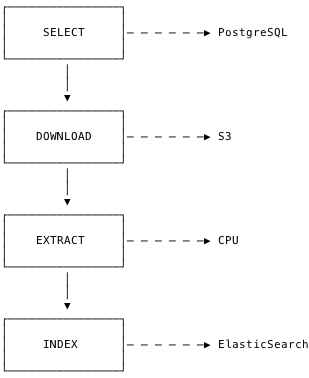
Задание можно представить в виде конвейера, состоящего из четырёх этапов:
-
SELECT – выбор записи из базы данных
-
DOWNLOAD – загрузка pdf-файла
-
EXTRACT – извлечение текста из файла
-
INDEX – индексация текста
Так как в данном случае речь идёт о сотнях тысяч записей, мне пришлось поразмыслить над тем, как сделать конвейер наиболее эффективным.
В результате мне удалось уместить реализацию эффективного алгоритма параллельной обработки данных всего в несколько строк кода.
Постановка задачи
Прежде чем предлагать какие-либо решения, необходимо как можно лучше разобраться в условии задачи.
Каждый этап будущего конвейера включает определённый набор действий и особенностей реализации:
-
SELECT: Необходимо выполнить SQL-запрос, который возвратит 100 000 записей. Лучше всего использовать курсоры PostgreSQL, а новая функция Repo.stream упростит этот процесс. Этап будет выполняться снова и снова, обеспечивая непрерывный поток записей.
-
DOWNLOAD: На данном этапе реализуется сетевой ввод-вывод данных, который достаточно легко распараллелить.
-
EXTRACT: Извлечение текста – задача CPU, которая тоже может выполняться параллельно на нескольких ядрах процессора.
-
INDEX: В ElasticSearch гораздо производительнее индексировать файлы не отдельно, а пакетами.
Проведя такой простой анализ, можно нарисовать полную картину того, над чем придётся работать. Кроме того, решение этой задачи в полной мере иллюстрирует работу GenStage, а особенно Flow.
Реализация
GenStage разделяет этапы конвейера на три типа:
-
Поставщик (Producer) – порождает события (этап SELECT)
-
Поставщик-потребитель (Producer-Consumer) – получает одни события и порождает другие (этапы DOWNLOAD и EXTRACT)
-
Потребитель (Consumer) – получает события, при этом не порождая новых (этап INDEX)
@spec select :: Stream
def select, do: ...
@spec download(record) :: file
def download(record), do: ...
@spec extract(file) :: text
def extract(file), do: ...
@spec index([text]) :: nothing
def index(texts), do: ...Каждый этап можно представить в виде простой функции:
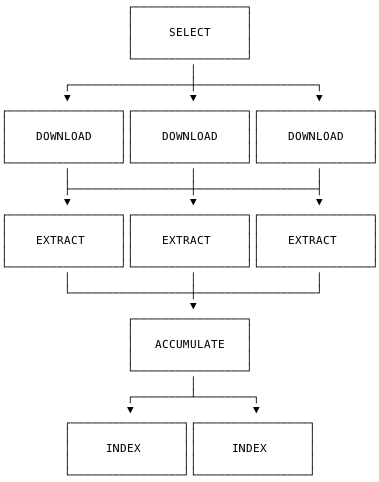
Весь конвейер выглядит следующим образом:
-
Один этап SELECT
-
Несколько этапов DOWNLOAD
-
Несколько этапов EXTRACT
-
Этап ACCUMULATE, объединяющий файлы для последующей индексации
-
Несколько этапов INDEX
Воплотить всё это в жизнь можно с помощью следующих 12 строк кода:
def perform do
# вызываем функцию select/0, чтобы получить поток данных
select
# конвертируем его во Flow
|> Flow.from_enumerable(max_demand: 100)
# распределяем поток записей между 50 процессами
|> Flow.partition(max_demand: 100, stages: 50)
# в каждом процессе вызываем функцию download/1 для каждой полученной записи
|> Flow.map(&download/1)
# получаем поток файлов, который снова распределяем между 50 процессами
|> Flow.partition(max_demand: 100, stages: 50)
# в каждом процессе вызываем функцию extract/1 для каждого полученного файла
|> Flow.map(&extract/1)
# чтобы провести индексацию файлов пакетами,
# объединяем их в текстовые фрагменты по 100 строк с помощью функции Window.count/1
|> Flow.partition(window: Flow.Window.count(100), stages: 1)
# передаём в функцию Flow.reduce/2 два аргумента:
# - функция-аккумулятор, вызываемая в начале обработки каждого фрагмента
# - функция свёртки, вызываемая для каждого элемента фрагмента
# Таким образом мы помещаем входящие элементы в список.
|> Flow.reduce(fn -> [] end, fn item, list -> [item | list] end)
# события потока всё ещё представляют собой отдельные текстовые строки, поэтому
# нужно сделать так, чтобы Flow превращал в события состояния функции свёртки
|> Flow.emit(:state)
# наконец, воспользуемся той же функцией Flow.partition, чтобы запустить 10 процессов
|> Flow.partition(max_demand: 100, stages: 10)
# вызываем функцию index/1 для каждого списка из 100 строк
|> Flow.map(&index/1)
# в заключении, запустим поток, который будет блокироваться,
# пока конвейер не завершит свою работу.
|> Flow.run
endИ это всё?
К сожалению, нет. Придётся ещё немного попотеть.
Оптимизация
В примере выше переменные max_demand и stages имели произвольные значения. Несмотря на то, что приведённый код работает безошибочно, его производительность далека от идеальной. Для наглядности приведу график, полученный после обработки 700 записей.
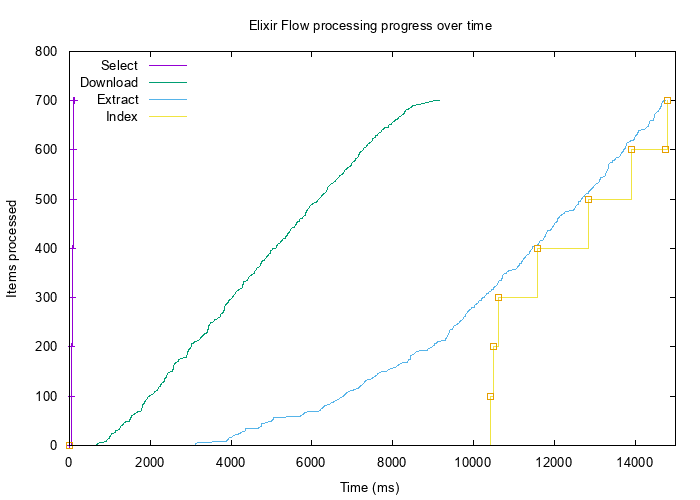
Кривые на графике показывают количество обработанных на определённом этапе элементов в единицу времени. Можно видеть, что на этапе SELECT действия по выборке 700 записей из базы данных и помещению их в память осуществились мгновенно. Извлечение текста на этапах EXTRACT начало выполняться с задержкой в 3 секунды (когда уже было загружено почти 200 файлов). Индексация также началась очень поздно (в очереди уже находились 300 текстовых элементов).
В конвейерах такого рода производительность отдельных ступеней не так важна, как производительность конвейера в целом. Обрабатывая большие объёмы данных, обычно стремятся к тому, чтобы вся система была стабильна по части использования ресурсов.
Поэкспериментировав с различными значениями (и построив несколько графиков для разных случаев), я остановился на следующем:
def perform do
select
|> Flow.from_enumerable(max_demand: 100)
|> Flow.partition(max_demand: 5, stages: 10) # instead of 100 and 50
|> Flow.map(&download/1)
|> Flow.partition(max_demand: 5, stages: 4) # instead of 100 and 50
|> Flow.map(&extract/1)
|> Flow.partition(window: Flow.Window.count(100), stages: 1)
|> Flow.reduce(fn -> [] end, fn item, list -> [item | list] end)
|> Flow.emit(:state)
|> Flow.partition(max_demand: 20, stages: 2) # instead of 100 and 10
|> Flow.map(&index/1)
|> Flow.run
endРезультаты получились намного лучше:
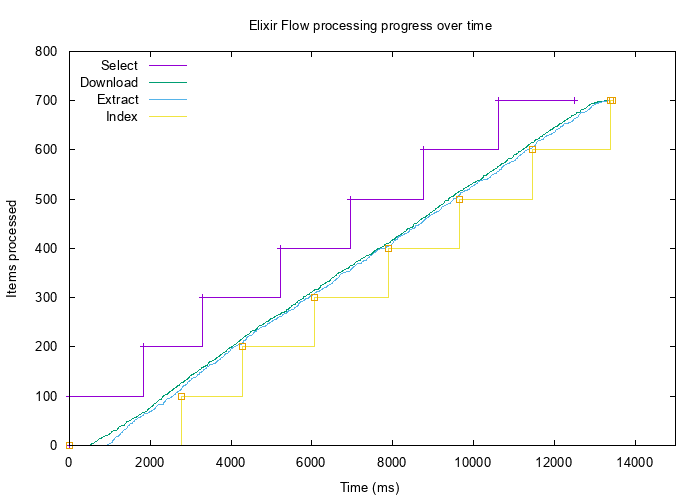
С такими подстроенными параметрами все этапы конвейера обрабатывают данные с минимальной буферизацией и низким потреблением памяти. Сам конвейер также отработал немного быстрее, но так как имеем дело с внешними сервисами, этот случай не подойдёт в качестве теста скорости.
Заключение
GenStage и его высокоуровневая "оболочка" Flow предоставляют необходимые средства для реализации эффективной параллельной обработки данных. Какой бы волшебной ни казалась эта возможность, забывать об оценке производительности не стоит. И всё же я уверен, что при достижении "правильного" показателя производительности система будет иметь большой потенциал по масштабируемости, обеспечивая низкий расход ресурсов при работе с большими объёмами данных.