Проектирование P2P-площадки взаимного кредитования на Elixir
В данной статье мне бы хотелось осветить процесс разработки одного из наших последних проектов — рыночной площадки P2P, предназначенной для использования в целях секьюритизации портфелей одной очень крупной онлайн кредитной организации и портфелей многочисленных инвесторов. Я расскажу о том, как безумное на первый взгляд решение о смене стека технологий оказалось отличной идеей.
Зачем мне это? Чтобы привлечь новых разработчиков и спонсоров в сообщество Elixir. Вряд ли я смог бы назвать себя предприимчивым, но я знаю, что первое, что им пришло бы на ум, — это вопрос: «Какие проекты уже реализованы на Elixir?». Найти хорошие примеры в сети не так-то просто.
Предупреждение: я постараюсь держаться как можно ближе к сути проекта с технической точки зрения, но есть несколько связанных с бизнесом вопросов, которые нельзя оставить без внимания.
Бизнес-задачи
Представьте, что вы владеете кредитной организацией. А значит, изо дня в день вы даёте людям кредиты, получаете проценты, если они их погашают или теряете деньги в противном случае. При наличии хороших маркетинговых каналов и умения разбираться в людях ваш бизнес будет процветать, расти и приносить прибыль.
Но наступит момент, когда из-за большого количества выданных займов на новый кредит ваших финансов уже не хватит, и бизнес приостановится.
Может, вы начнёте искать инвесторов, которые выкупят часть вашего кредитного портфеля и, возможно, разделят ваши риски. Процент прибыли с каждого кредита снизится, но это можно будет компенсировать, развивая компанию дальше и сокращая риски.
Инвесторы могут быть избирательными — приобретать определённые кредиты, опираясь на результаты своего технического анализа, статистику или просто интуицию. К примеру, они захотят, чтобы портфель на 75% состоял из кредитов, выданных в Испании молодым людям от 28 до 35 лет с хорошей кредитоспособностью и высоким доходом (малый риск/низкая прибыль); и на 25% из кредитов, выданных любым людям с низкой кредитоспособностью (большой риск/высокая прибыль).
И где же вам с инвестором искать друг друга? На торговой площадке, где кредиторы смогут размещать информацию о кредитах, а инвесторы — свои ожидания; где данные активов дополнительно оцениваются и им подбирается лучшее предложение инвесторов; где следят за жизненным циклом каждого актива, защищая интересы обеих сторон за небольшую плату.
Общие положения и дополнительные требования
- С первого дня существования площадки нужно быть готовым к обработке сотен тысяч кредитов в день и постоянного обновлений их состояния. Это не стартап, человек с мешком денег уже готов с вами сотрудничать;
- Поддержка проекта должна быть передана третьему лицу после завершения стадии активной разработки, чтобы ничто не мешало продолжать создавать новые проекты;
- Конфигурации должны быть достаточно гибкими, чтобы предприниматели могли экспериментировать с программными продуктами без необходимости их доработки;
- Ограничения по ресурсам: 6 месяцев, ~10 разработчиков, несколько аналитиков и бизнесменов;
- Необходимо сделать интеграцию как можно проще как для кредиторов, так и для других сторон. Доработка обойдётся гораздо дороже, чем разработка;
- Это сфера финансовых технологий. Здесь данные не могут быть потеряны, а все операции должны быть отслеживаемыми. Для проектов такого рода даже проблемы с обработкой чисел с плавающей точкой могут стать бомбой замедленного действия. Должно быть соблюдено множество правовых норм;
- Планы на будущее: кредиты — не единственный актив, которым можно торговать (в рамках данной статьи понятия «кредит» и «актив» эквивалентны), следовательно, в дальнейшем площадка может развиваться во многих направлениях.
Риск перехода к новому стеку технологий
До проекта торговой площадки наша команда работала с PHP, MongoDB, Puppet и Angular.js, но мы взяли на себя риск, решив резко перейти к совершенно новому набору серверного ПО — Elixir, PostgreSQL, RabbitMQ, Docker, Kubernetes и React.js+Redux.js, что оказалось верным решением, как по части развития навыков членов команды, так и благодаря многочисленным преимуществам данного стека, а именно:
- Намного более чистый код, который проще создавать и поддерживать;
- Отказоустойчивость;
- Конкурентное выполнение;
- Потоковая обработка данных;
- Единые бинарные файлы для всех окружений;
- Никакой возни с различными правилами установки серверов для различных окружений;
- Хорошо структурированные интерфейсные приложения и визуализация на стороне сервера;
- Наша команда аналитиков когда-то работала над спецификацией для BPMN нотации, которая благодаря сопоставлению с образцом и легковесным процессам отлично соотносится с кодом.
Вы спросите, как так получилось?
Еще летом 2016 года один мой друг обмолвился об Elixir — новом подающем надежды языке программирования. В тот момент я было подумал, что это просто ещё один бесполезный язык, но всё же решил попытать счастья и реализовать на нём новый микросервис.
Я изучил всю документацию на официальном сайте, посмотрел несколько роликов на YouTube и сел за код. В первые дни меня не покидало ощущение, что хорошего в Elixir мало, и всё это зря. Потом я подумал, что, может, я просто недостаточно компетентен, чтобы разглядеть все преимущества. Спустя неделю функциональное программирование сломало систему моего мышления, и я влюбился в Elixir.
Ecto 2.0 не взаимодействует с MongoDB, и я установил базу PostgreSQL и решил теперь работать с ней. Это решение также было навеяно постом Кайла Кингсбери о потере данных в MongoGB и поддержке индексов JSONB в PostgreSQL.
Процесс создания кода упростился, и я чувствовал, что никогда не был настолько продуктивным, до тех пор, пока не попытался запустить свой сервис. Оказалось, что компиляция была платформозависимой. Для решения этой проблемы мне пришлось создать образ виртуальной машины. Можно также реализовать Docker-контейнер, характеризующийся более удобной поставкой и оптимизированным жизненным циклом разработки. Кроме этого, я написал приёмочные тесты для контейнеров, чтобы убедиться, что после компиляции кода в OTP он работает во всех окружения. Этого мне как раз и не хватало в моей прошлой PHP-жизни.
Единые конфигурации релиза — ещё одна проблема, которую пришлось решать. Чтобы один и тот же контейнер можно было использовать во всех окружениях, он должен конфигурироваться во время выполнения, но в Elixir реализовать такое крайне непросто. Можно установить в контейнере переменную окружения REPLACE_OS_VARS и начать использовать bash-образные переменные в конфигурациях, но что если вам вдруг понадобится целочисленное значение? На помощь придёт Confex.
Поскольку мне больше не хотелось возиться с настройкой сервера, контейнеры я решил запускать через Kubernetes. С его помощью развёртывание и поддержка приложений идёт как по маслу.
Общая схема площадки
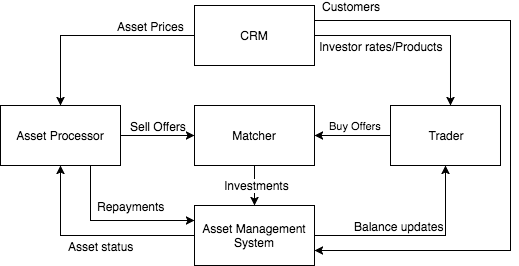
Проанализировав все требования, торговую площадку можно разделить на несколько отдельных компонентов (предметных областей?) по их назначению:
- Обработчик активов (Asset Processor), где происходит обмен информацией с кредиторами, обработка полученных от них данных и создание предложений продажи;
- Продавец (Trader), представляющий собой продающий бот, который генерирует предложения покупки в соответствии с критериями инвесторов;
- Сопоставитель (Matcher), устанавливающий соответствие между предложениями покупки и продажи и создающий данные, необходимые для осуществления инвестиций;
- Система управления активами или главная бухгалтерская книга (Asset Management System), обрабатывающая эти данные и осуществляющая инвестиции, перемещающая деньги между счетами, создающая отчеты и не допускающая технических овердрафтов;
- CRM-система — центральное звено управления жизненным циклом клиента и конфигурациями.
Asset Processor
Основные задачи:
- Обмен информацией с кредиторами;
- Хранение и пополнение баз данных;
- Создание предложений продажи.
В целях уменьшения стоимости интеграции для кредиторов, не будем вынуждать их запоминать последние отправленные на платформу данные и производить их постоянное обновление. Вместо этого они могли бы один раз в конце дня высылать массив актуальных данных, а изменения будем отслеживать мы. Это означает, что хранение данных — задача площадки.
Поскольку эти данные не имеют сильной связи, проблема масштабирования базы данных не возникает — можно сегментировать данные в виде: клиент (кредитор), его ID и ID актива (кредита).
Обмен информацией
Прежде всего, нужно продумать, как организовать получение и обработку больших массивов данных от клиентов. Простое решение с REST JSON API не подойдёт, потому что:
- Установление связи для каждого отдельного актива — дорогостоящая операция. Нам это по силам, но для кредиторов такая задача может обойтись недёшево из-за унаследованных данных в их системах. Следовательно, данные должны быть получены пачками;
- На стороне кредитора большинство изменений происходят не в реальном времени, а по завершении операционного дня. Пачки могут быть достаточно объёмными;
- Для некоторых случаев всё-таки необходимо обновление данных в течение дня, например, когда кредитор желает отозвать выплаченный займ, прежде чем его перекупит инвестор. Понятие «конец дня» для каждого клиента отлично;
- Документы в формате JSON возможно обработать, только загрузив весь файл в память.
JSON был заменён на BSON. Это позволяет производить отложенное чтение файлов по порядку, что легко реализовать на Elixir. Существует множество библиотек для большинства других языков программирования, которые могут послужить в качестве кодировщиков JSON и обеспечить менее болезненную интеграцию.
Итак, мы создали единую конечную точку для пакетной выгрузки файлов в формате BSON. Кредитор отслеживает изменение данных с прежней загрузки, записывает эти данные в файл BSON и отправляет его нам.
Для обратной связи было решено сделать нечто похожее — создать простенький микросервис, считывающий сообщения в очереди и сохраняющий их в файл на диске. По прошествии какого-то времени этот файл высылается кредитору, очищается и процесс повторяется снова.
Хранение и обработка данных
Получив пачку файлов с данными, необходимо его обработать и сохранить его резервную копию на Amazon S3 (она может пригодиться позже для порождения событий). Что нужно сделать:
- Найти обновлённые данные для каждого актива и предписать действие: удалить предложение продажи, создать или обновить его, послать уведомление системе управления активами о выплате кредита.
- Сохранить изменения в базе данных;
- Дополнить данные — предсказать денежный поток и в соответствии с его величиной и другими данными кредитора разделить все кредиты на три группы риска.
Вначале чтение файлов производилось рекурсивно, и пул соединений к базе данных стал заполняться очень быстро. Лучше всего такие проблемы решаются использованием «противодавления» во время обработки данных. Здесь нам поможет GenStage.
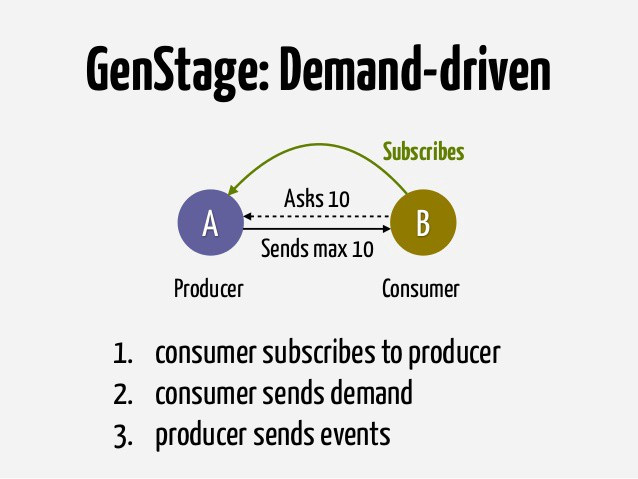
Благодаря ему сократилось использование памяти для большого массива данных (с нескольких Гб до почти постоянного значения 56 Мб) и прекратилась перегрузка пула соединений к БД. В итоге все части обработчика активов и некоторые другие места были переписаны с использованием нескольких GenStage.
Обработчик активов можно разделить на несколько частей:
- Интеграционный слой (ИС) — основной компонент, который получает пачки файлов и принимает решение о том, как следует их обрабатывать, а также направляет данные в соответствующие очереди. Это своего рода владелец бизнес-процесса;
- Оценщик (Assessor) — вычисляет денежный поток и распределяет активы по группам риска;
- Сборщик (Merger) — эффективно помещает дополненные данные обратно в базу.
Вот как может выглядеть конвейер обработки данных для новых активов:
- ИС/Наблюдатель: запускает новый производитель GenStage, новый процесс для загрузки резервной копии файла и ожидает, пока производитель достигнет конца файла. Как только данные загружены и обработаны, удаляет файл;
- ИС/Производитель (создаётся динамически): выполняет отложенное чтение файла (через BSONEach) и уведомляет наблюдателя, когда достигнут конец файла;
- ИС/Производитель-Потребитель: посылает запрос к базе данных для получения последней сохранённой версии данных актива;
- ИС/Производитель-Потребитель: вычисляет разницу между двумя состояниями и направляет данные соответствующему потребителю;
- ИС/Потребитель: отправляет сообщение в RabbitMQ-очередь под названием
Assessor.In; - Оценщик/Потребитель: считывает сообщения в очереди
Assessor.In; - Оценщик/Производитель-Потребитель: посылает вызов к REST API сервиса для подсчёта денежного потока (ещё один наш проект) и дополняет данные вместе с ответом;
- Оценщик/Производитель-Потребитель: посылает REST API ещё один такой же вызов и снова дополняет данные;
- Оценщик/Производитель: ставит сообщение в RabbitMQ-очередь под названием
Assessor.Outи подтверждает его обработку вAssessor.In; - ИС/Потребитель-производитель: перемещает сообщения из
Assessor.Inв очередьMerger.In(это для того, чтобы держать под контролем весь бизнес-процесс в ИС); - Сборщик: считывает сообщение в очереди
Merger.In, записывает данные в базу и помещает сообщение в очередьMerger.Out; - ИС/Маршрутизатор: считывает сообщение из этой очереди, записывает данные в структуру предложения продажи и сворачивает их в сообщение, предназначенное для Сопоставителя.
Такая схема может показаться чересчур усложнённой, но именно она будет вашим козырем в рукаве в сотрудничестве с корпоративными клиентами: они смогут заменять компоненты или использовать их повторно, а сама бизнес-логика фактически будет находиться только в одной части системы.
Порождение событий
Резервные копии полученных файлов и содержимое нашей базы данных являются неизменяемыми. Вместо использования оператора обновления будем увеличивать версию существующей записи и переписывать её в новую строку.
Таким образом, можно гарантировать, что каждый актив каждой пачки будет обработан всего один раз. Это нужно для осуществления полноценного перезапуска пачки задач и поиска дубликатов сообщений в очереди (на практике обеспечить отсутствие дубликатов очень сложно).
Кроме того, перезапуск обработки пачек будет возможен как с удалением данных из базы, так и без него, что сэкономит множество ресурсов в продакшне.
Есть одна замечательная статья об иммутабельных данных. Мне всегда нравилось работать над проектами с неизменяемым постоянным хранилищем: это обеспечивает отслеживаемость данных на стадиях разработки и реализации, повышает уровень защиты данных и упрощает процесс сопровождения ПО.
Конечно, от проблемы быстрого роста размера БД никуда не деться, но можно бороться с ней посредством сохранения старых версий данных или моментальных снимков БД, удаляя оттуда всё, что не относится к бизнес-процессам.
Trader
Основные задачи:
- Создание REST JSON API для инвесторов (фронтенд);
- Сохранение критериев подбора активов в базе данных;
- Генерация предложений покупки в соответствии с этими критериями;
- Поддержка состава портфеля.
Trader — одна из самых простых составляющих нашей торговой площадки. Главные особенности Trader — это API на Phoenix и микросервис «Gap Analyzer», получающий текущее состояние портфеля и генерирующий новые предложения покупки.
Gap Analyzer
Когда инвестор создаёт портфель, состоящий из активов различного рода (разобьём их на три группы по степени риска), нужно убедиться, что баланс между ними не нарушен. Иначе, учитывая текущее состояние рынка, спрос на кредиты с высокой степенью риска может значительно превышать спрос на кредиты с низкой степенью риска, в результате чего состав портфеля не будет удовлетворять ожидания клиентов, и это приведёт к потере капитала. Чтобы уравновесить эту разницу, мы решили создавать предложения продажи (одно для каждой группы) только для небольшого количества активов портфеля (10%):
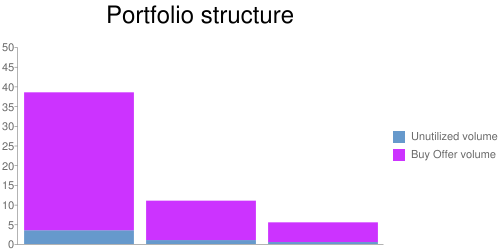
После того как предложение было принято и равновесие активов восстановлено (например, спрос для первой группы был удовлетворён), начинается новый торговый цикл. Группы пополняются новыми активами пропорционально общей структуре:
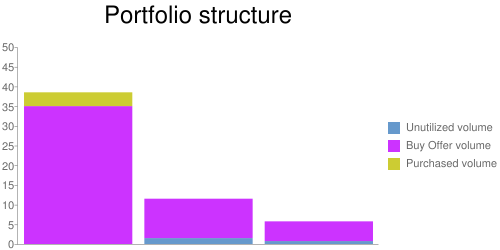
Цикл повторяется снова до тех пор, пока все активы не будут задействованы. Если какая-то из групп не пополняется, то следует ожидать поступления новых активов. Нарушить структуру можно лишь на несколько процентов от общего объёма.
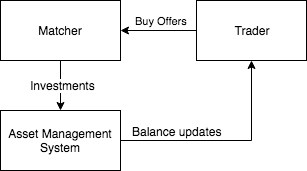
Matcher
Основные задачи:
- Сопоставление предложений продажи с предложениями покупки;
- Вычисление цены покупки/продажи в соответствии с условиями (инвесторы могут указать свои процентные ставки);
- Отправка данных к Asset Management System.
Matcher считывает сообщения из очередей предложений покупки и продажи, сопоставляя их и пытаясь добиться наивысшей выгоды. Эти действия могут быть выполнены в RAM, а если какие-либо данные будут утеряны, можно ввести их заново, обратившись к Trader или Asset Processor.
Чаще всего инвесторы приобретают не весь кредит целиком, а малые доли в большом количестве займов, тем самым снижая свои риски.
Важно отметить, что для некоторых активов такая схема невыполнима, так как инвестиции для них создаются только тогда, когда инвесторы будут найдены для всех существующих предложений продажи. Поэтому, необходимо в первую очередь обработать наиболее «продаваемые» активы, иначе деньги инвесторов могут быть вложены в актив, который никто никогда не перекупит.
Как только приходит новое предложение продажи, оно анализируется, и к нему подбирается предложение покупки. При каждом сопоставлении рассчитывается цена покупки и продажи (разница между ними составляет наши проценты) и для каждой пары назначается цена Bid. Если достигнуто допустимое количество предложений продажи или возможна частичная продажа, отправляется сообщение с предложением продажи и информацией обо всех ценах Bid.
При поступлении предложения покупки имеем схожий порядок действий: выполняется поиск всех предложений продажи, удовлетворяющих заданные критерии, а допустимое количество предложений покупки уменьшается в соответствии с количеством полученных цен Bid. Если достигнуто допустимое количество предложений покупки, их поступление прекращается. В противном случае предложения покупки продолжают поступать и сопоставляться с предложениями продажи.
При поступлении запроса на обновление предложения, необходимо откатить все изменения до предыдущей версии и снова начать сопоставление (здесь нужно ещё подумать надо оптимизацией).
Знакомьтесь, Mnesia
В Erlang и Elixir имеется база данных Mnesia, которая хранится в том же объёме памяти и обеспечивает поиск с низкой задержкой.
Поскольку время работы над данным проектом было ограничено, наша команда приняла решение вести разработку с PostgreSQL и создать адаптер Ecto в качестве упрощённой замены.
Asset Management System
Основные задачи:
- Подсчёт капиталовложений инвесторов;
- Контроль над соблюдением всех норм;
- Уведомление Trader о нарушении равновесия в портфеле.
Вместо создания AMS с нуля мы приобрели SaaS-сервис, умеющий делать всё, что нужно, и просто написали обёртку над его API.
Функционирование торговой площадки заключается в запуске торговых циклов, выполнение сопоставления для каждой сделки по активу требует больших затрат, в связи с чем с помощью GenServer мы отложили на 30 секунд события, возникающие при нарушении равновесия в составе портфеля, следовательно, к Trader посылаются только совокупные данные.
CRM
Эту часть мы также заимствовали: мы взяли CRM, являющуюся одной из лидеров в магическом квадранте Gartner и создали обёртку над ней.
Правовые рамки
Один из наиболее щепетильных вопросов ведения бизнеса — это вопрос о правовых рамках. Возможно, однажды вам захочется внести поправки в юридическое соглашение, но, в соответствии с правовыми нормами, это может быть сделано только с согласия инвесторов. Поэтому, при желании запустить новый проект, придётся составить новый публичный договор и запросить согласие инвесторов, прежде чем предлагать им товар.
API Gateway
Разрабатывая большой проект с микросервисной архитектурой, иногда приходится совершать одни и те же типичные манипуляции (управление доступом, валидация, логгирование) снова и снова. В нашем случае было решено создать API на Elixir с открытым исходным кодом, который выполнял бы все эти действия, облегчая код всех остальных сервисов.

Документация содержит всю необходимую информацию, которая поможет вам разобраться с нюансами его работы.
Возникшие проблемы и пути их решения
Большое количество микросервисов
Первая реализация Asset Processor состояла приблизительно из 10 микросервисов, что буквально завалило нашу немногочисленную команду работой. При каждом изменении модели данных, скриптов непрерывной интеграции и др. мы вынуждены были повторно принимать это изменение снова и снова.
Проще говоря, мы извлекали весь связанный с Ecto код, помещали его в отдельный репозиторий GitHub и включали его в список зависимостей в каждом модуле проекта. Но ведь бизнес-логика раскидана по нескольким модулям, значит, придётся обновлять их все, и тесты тоже, либо перестраивать все контейнеры после каждого изменения в этой зависимости.
Перекроив код, мы остановились на трёх микросервисах (большинство из них было заменено производителями-потребителями GenStage/Flow).
Это же Elixir! В большинстве случаев микросервисы вообще не понадобятся! Советуем обратить внимание на OTP-приложения. Правило, проверенное временем:
Если хочется развернуть что-либо отдельно, используйте для этого отдельный микросервис, в другом случае — создавайте контекст или OTP-приложение в рамках большого проекта.
Микросервисы — это всего лишь способ упростить код, привнеся сложность в коммуникационный уровень модели.
Защитное программирование и архитектура
Ещё один урок, уяснённый во время разработки Asset Processor.
Мне казалось, что из-за большого объёма данных, проходящих через платфотму RabbitMQ, ошибки были неизбежны. Иногда обмен heartbeat-пакетами между репликами может быть отложен из-за большого количества других данных, проходящих через протокол TCP между нодами. Это может привести к тому, что RabbitMQ будет «разрываться» между задачами, пока сеть не разгрузится. Возможна даже потеря данных.
Для решения этой проблемы была реализована достаточно сложная система хранения. Для каждой входящей пачки данных создавалась новая база данных (на отдельном виртуальном хосте), которая выступала в качестве временного хранилища. Каждое изменение сохранялось в эту БД, а RabbitMQ использовался только для обмена задачами (ID временной БД и ID актива) между микросервисами. По завершении анализа базу данных можно было удалить.
Так мы получили несколько дополнительных фич:
- известен статус обработки для всей пачки (это довольно непросто, если учесть, что все процессы асинхронны, и количество полученных данных неизвестно);
- в непредвиденных ситуациях промежуточную базу данных всегда можно удалить и начать обработку сначала.
Откровенно говоря, все эти функции оказались совершенно ни к чему, и мы вернулись к отправке сообщений через сохраняемые очереди RabbitMQ, и я не припомню, чтобы этот подход хоть чем-то мог разочаровать.
Супервизор и его дочерние процессы
При ошибке в работе супервизора, его дочерние процессы могут быть остановлены. Вроде бы очевидная вещь, но мы умудрились натворить с этим дел.
После получения сообщения у нас создавался новый процесс GenServer под контролем супервизора, который должен был запускать бизнес-логику. Этот процесс кроме данных содержал в себе тег подтверждения. Когда супервизор по какой-либо причине уничтожал своего потомка, теги были безвозвратно утеряны.
А так как конкурентность была ограничена числом предварительных выборок (максимальное количество неподтверждённых задач, приходящееся на рабочую ноду), без тегов RabbitMQ просто не отправляла дополнительные данные, ожидая завершения предыдущих задач. Ноды получали задания, которые невозможно было обработать. Иной раз это приводило к их зависанию, и спасти ситуацию могла только перезагрузка (при разрыве связи RabbitMQ назначала получателем сообщений другую рабочую ноду).
Взгляните на досуге на поведение GenTask, которое как раз призвано решить эту проблему.
Помощь сообществу
Сообщество Elixir пока немногочисленно: не стоит ожидать, что вы сможете найти в нём решение любой проблемы. Однако Elixir даёт прекрасную возможность создать это решение самому в считанные дни.
Если вы планируете запуск коммерческих проектов на этом языке, рассчитывайте время на разработку с запасом. И, пожалуйста, уделите немного своего времени, чтобы поделиться своими самыми полезными наработками с сообществом.
Благодарности
Я бы хотел поблагодарить Алекса за то, что познакомил меня с Elixir, свою команду за поддержку во время работы над проектом и всех тех, кто помог мне с вычиткой статьи.
И особая благодарность Жозе Валиму за оперативные ответы на GitHub и за попытки помочь всеми возможными способами.